数据安全技术前沿研究笔记(三)
数据安全技术之差分隐私
1.差分隐私的定义
差分隐私技术由于无需假设攻击者能力或知识背景,安全性可通过数学模型证明,作为一种前沿的隐私保护技术受到广泛的关注。它可以确保数据库插入或删除一条记录不会对查询或统计的结果造成显著性的影响
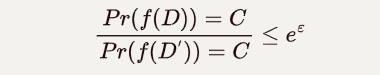
其中D 和 D′分别指相邻的数据集(差别只有一条建立),函数f是某种操作或算法(比如查询、求平均、总和等),对于输出C,两个数据集输出这样结果的概率几乎是接近的,即两者概率比值小于 e^ε ,那么称为满足 ε −ε隐私。一般来说,通过在查询结果中加入噪声,比如Laplace 类型的噪声,使得查询结果在一定范围内失真,并且保持两个相邻数据库概率分布几乎相同。ε 参数通常被称为隐私预算,ε 越小,两次查询的结果越接近,即隐私保护程度越高。
2.通俗解释
用通俗的例子来描述,可能会更好了解一些。假设存在一个数据库,这个数据库可以查询到人员的婚恋情况,如果一开始查询到有4个废物单身,只有2个有对象;这时跑来了个“诺”登记自己的婚姻状况,再查数据库发现5个人是单身,所以能够得出结论——“诺”也是废物。(这也就是差分的由来)

(图片来源与网络哦,不是俺弄的)
这里的”诺“作为样本的出现,使得攻击者猜出了他的局部信息,而差分隐私需要做到的就算使得攻击者不会因为新样本的出现而获取到新的信息和内容。它引入了随机噪声,原本的对应属性的数量耶呈现了概率分布的情况,简单而言就算,当你询问“诺”是否单身的时候,他有一定概率讲假话,这样子最大化数据查询的准确性,同时最大限度减少识别其记录的机会。
注:还没更完,周末咯!!!下班!
数据安全技术前沿研究笔记(三)
https://one-null-pointer.github.io/2022/08/12/数据安全技术之差分隐私/