图
图
1.图的定义
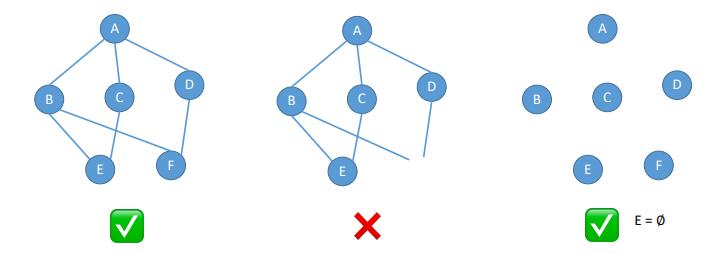
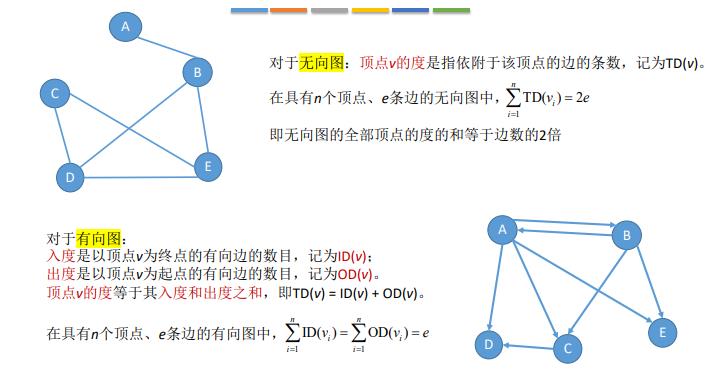
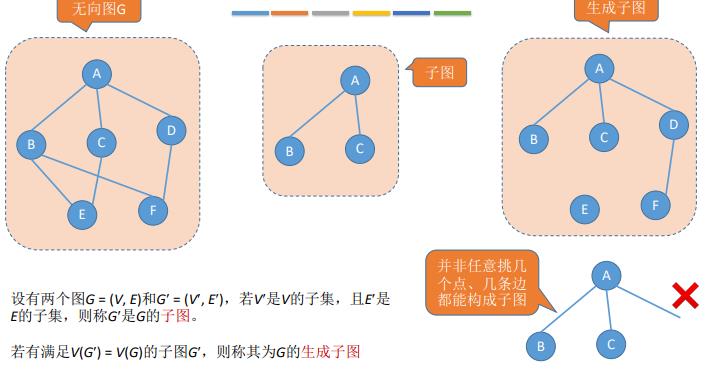
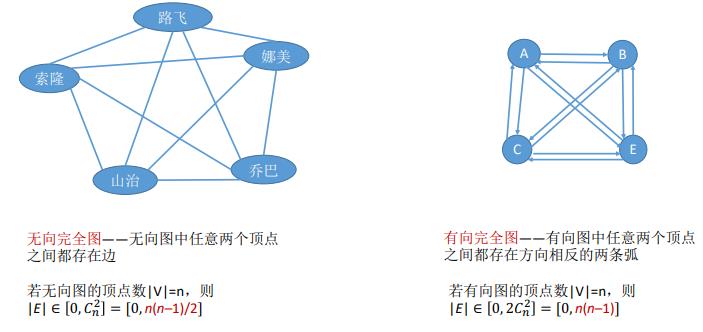
图G由顶点集V和边集E组成,记为G=(V,E),其中V(G)表示图G中顶点的有限非空集;E(G)表示图G中顶点之间的关系(边)集合。若V={V1,V2,V3,···,Vn},则用|V|表示图G中顶点的个数,也称图G的阶,E={(u,v)|u∈V,v∈V},则|E|表示图G中边的条数
注意:线性表可以是空表,数可以说空树,但是u不可以是空,也就是其中的V一定是非空集


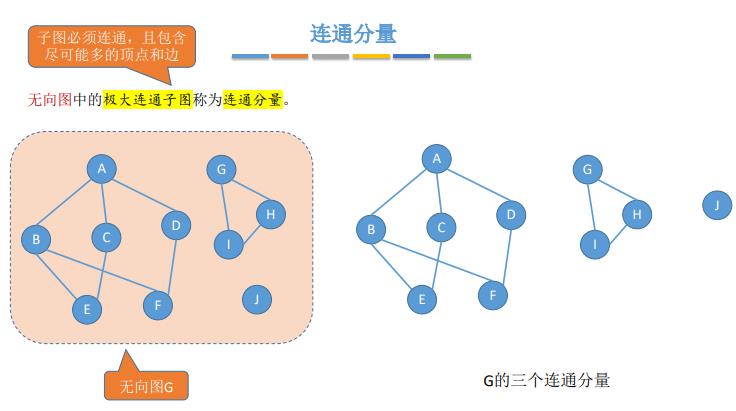
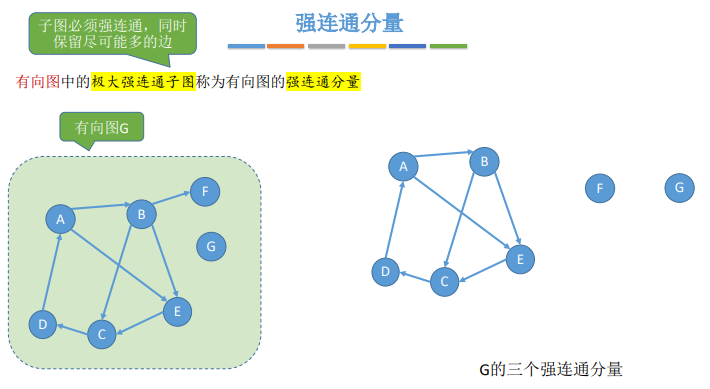
- 强连通分量
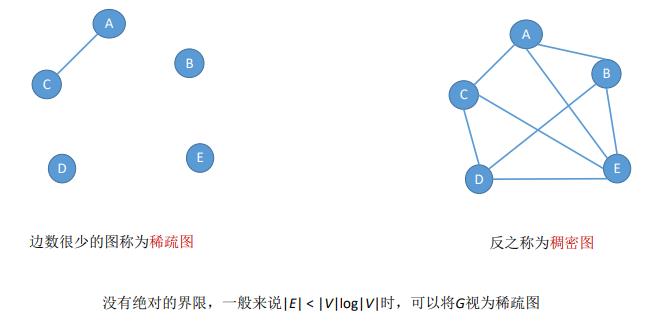

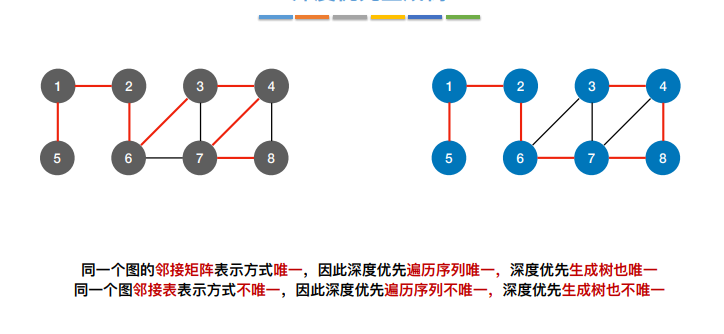
2.图的存储——邻接矩阵法
1 | |

1 | |

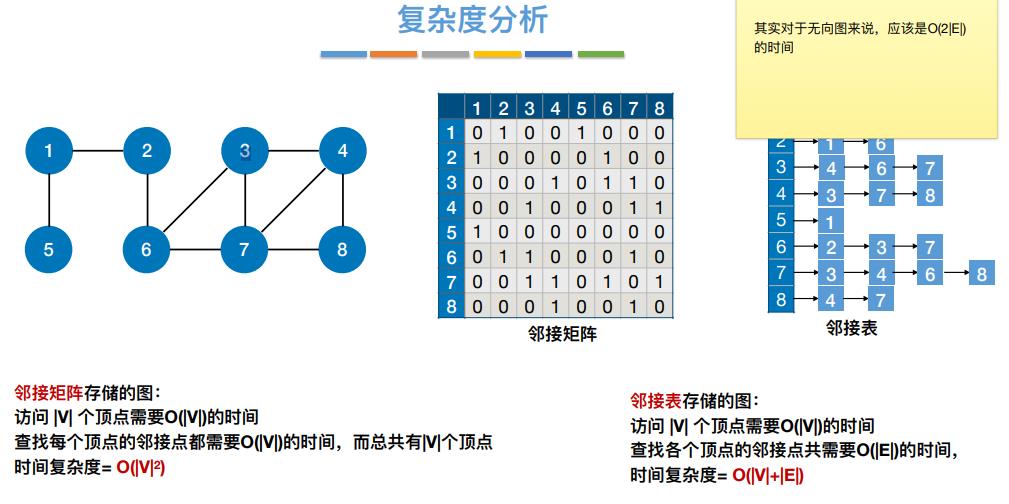
空间复杂度为:O(|V|²) ——只和顶点数相关,和实际的边数无关
可以看见在矩阵图存储中,会存在没有边的情况,如果一个图的边过少,则会浪费大量的存储空间,所以这种存储方式适用于存储稠密图,注:无向图的邻接矩阵是对称矩阵,可以压缩存储(只存储上三角区/下三角区)
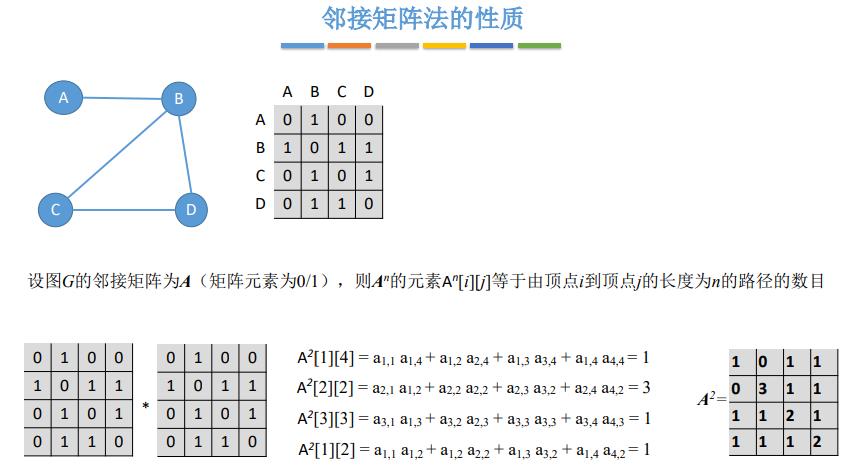

3.邻接表法(顺序+链式)
1 | |
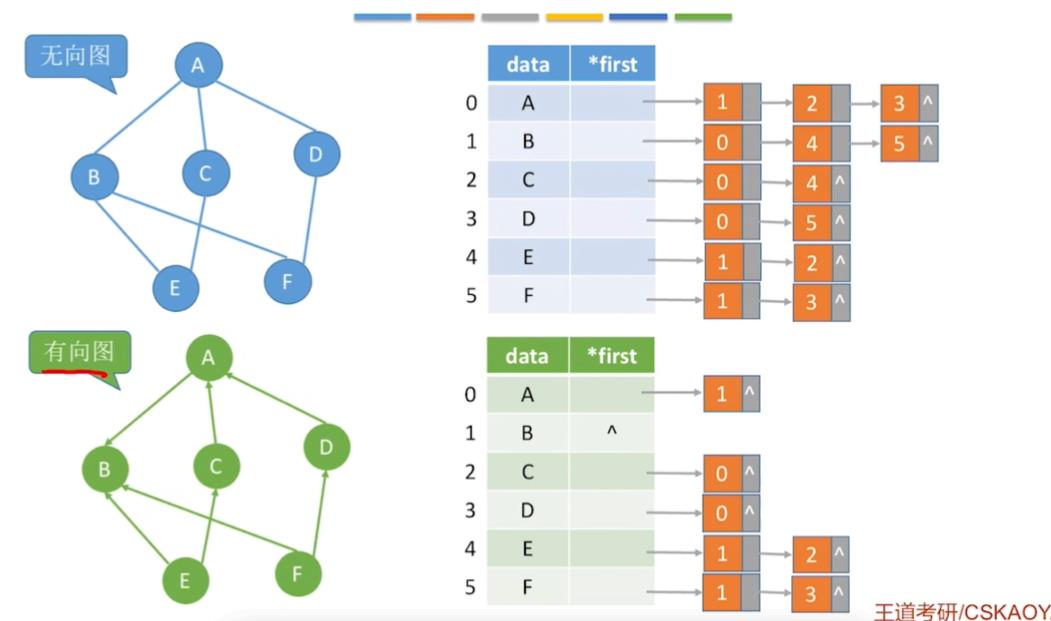

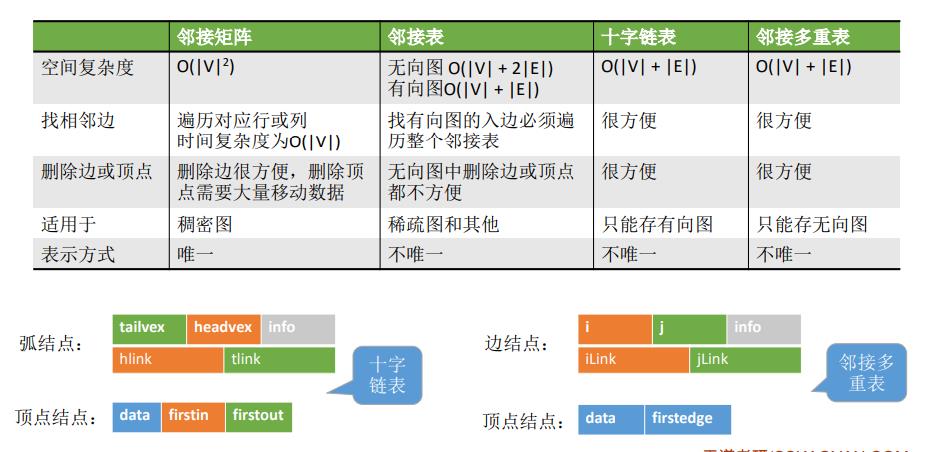
4.十字链表法
十字链表法只能用于解决存储有向图
空间复杂度:O(|V|+|E|)
5.邻接多重表
邻接多重表只适 用于存储无向图
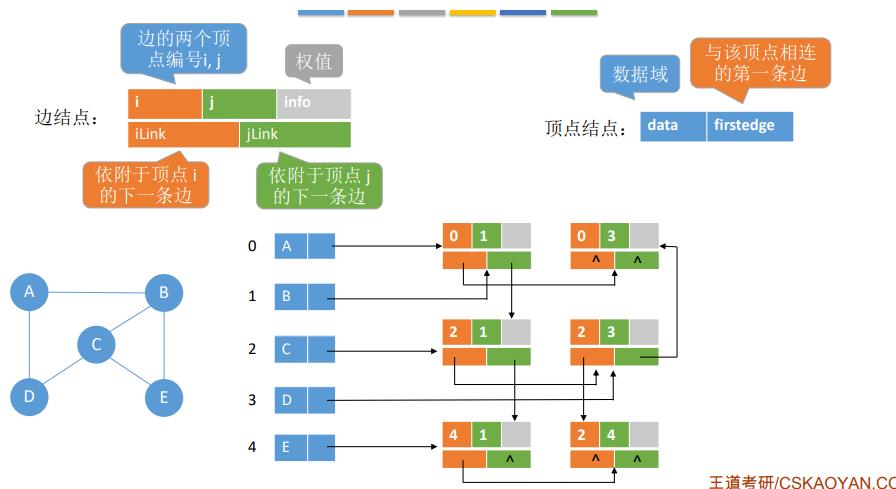
空间复杂度:O(|V|+|E|)
6.四种方法比较
7.图的基本操作
Adjacent(G,x,y):判断图G是否存在边或(x, y)。
Neighbors(G,x):列出图G中与结点x邻接的边。
InsertVertex(G,x):在图G中插入顶点x。
DeleteVertex(G,x):从图G中删除顶点x。
AddEdge(G,x,y):若无向边(x, y)或有向边不存在,则向图G中添加该边。
RemoveEdge(G,x,y):若无向边(x, y)或有向边存在,则从图G中删除该边。
FirstNeighbor(G,x):求图G中顶点x的第一个邻接点,若有则返回顶点号。若x没有邻接点 或图中不存在x,则返回-1。
NextNeighbor(G,x,y):假设图G中顶点y是顶点x的一个邻接点,返回除y之外顶点x的下一 个邻接点的顶点号,若y是x的最后一个邻接点,则返回-1。
Get_edge_value(G,x,y):获取图G中边(x, y)或对应的权值。
Set_edge_value(G,x,y,v):设置图G中边(x, y)或对应的权值为v。
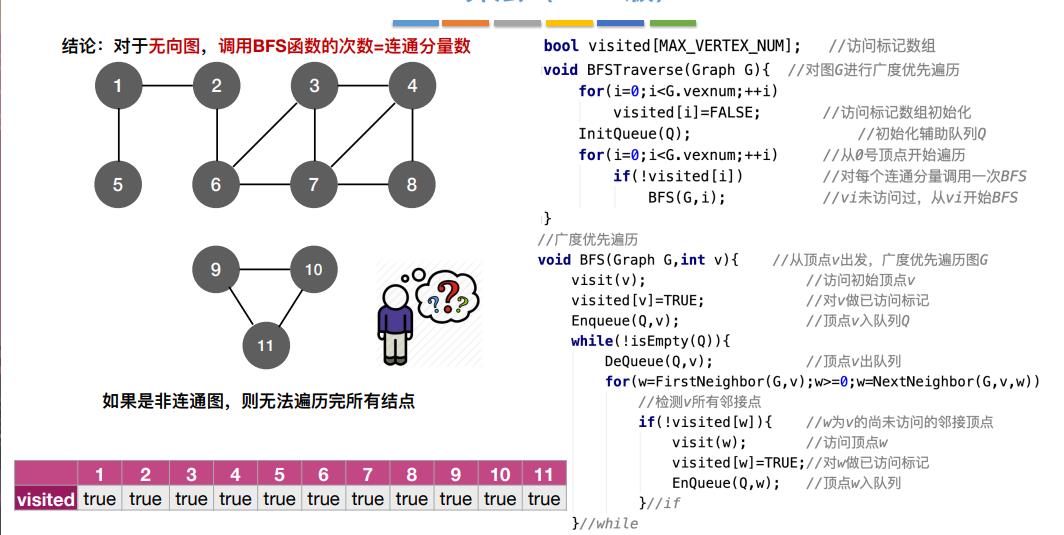
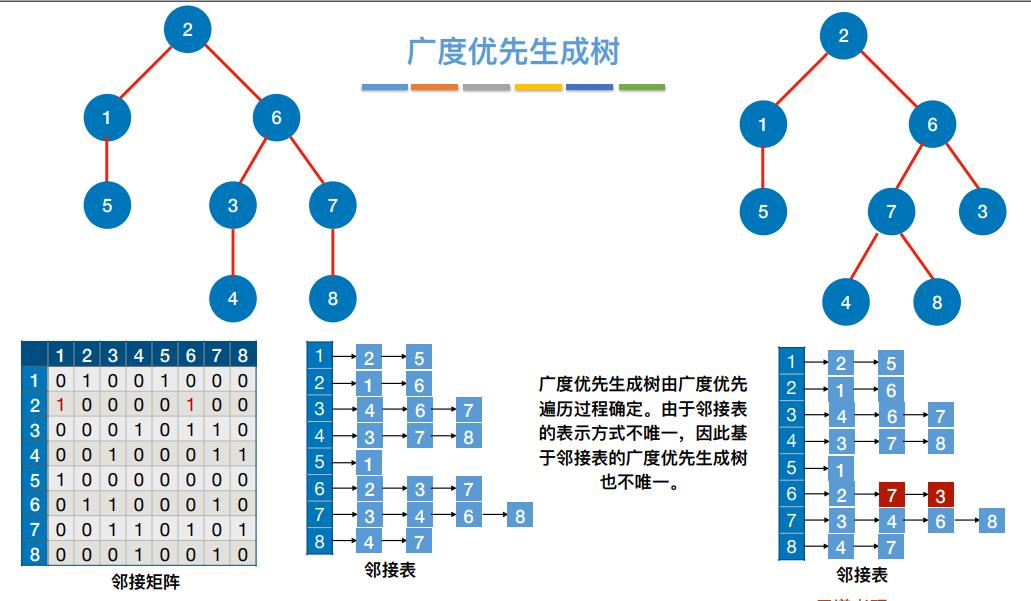
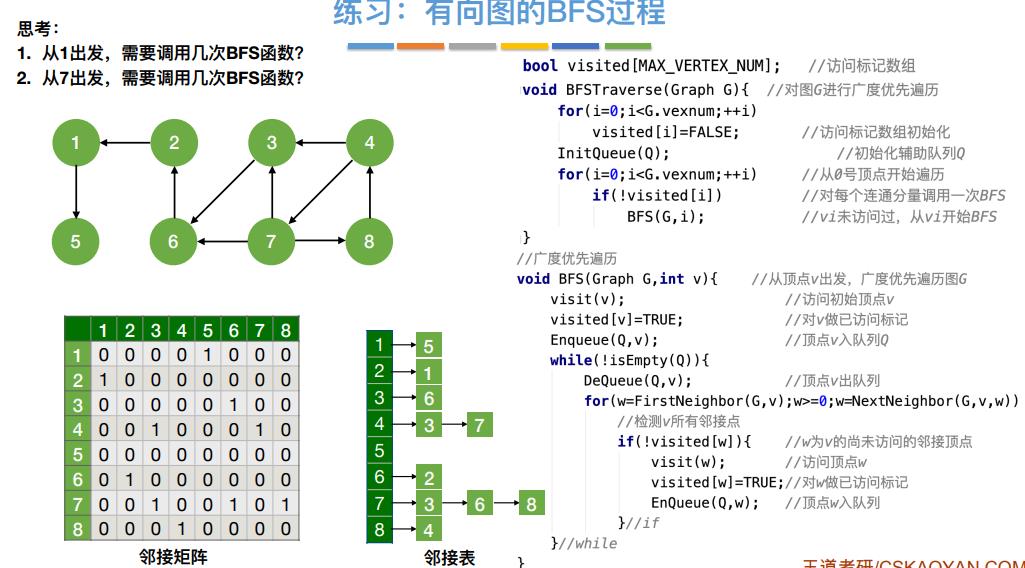
8.图的广度优先遍历算法

1 | |
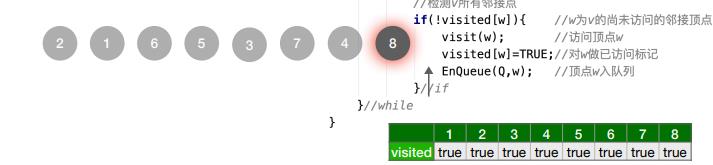
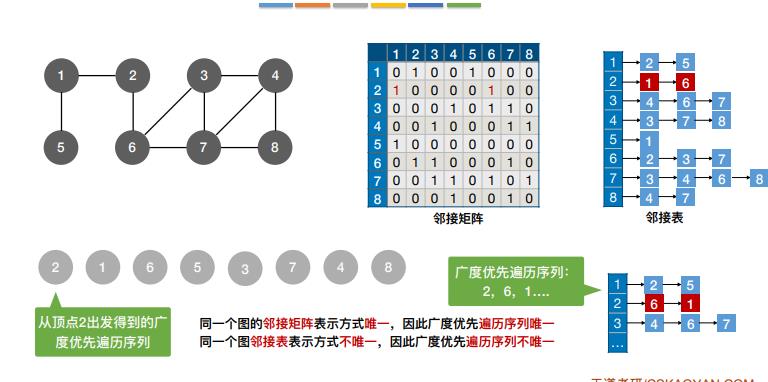
1 | |
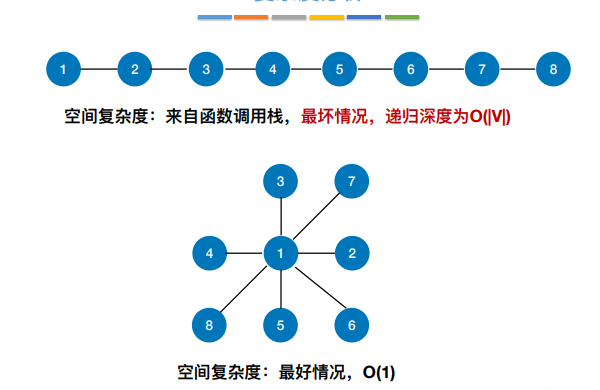
9.图的深度优先遍历
1 | |
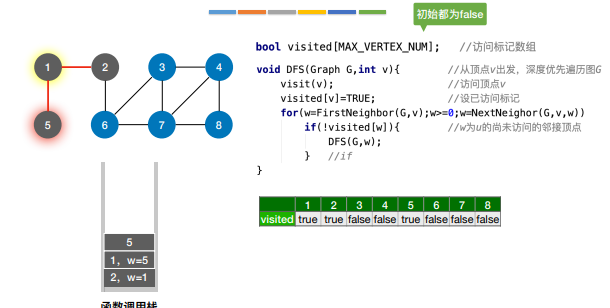
1 | |
解决了非连通图无法遍历完所有结点的问题

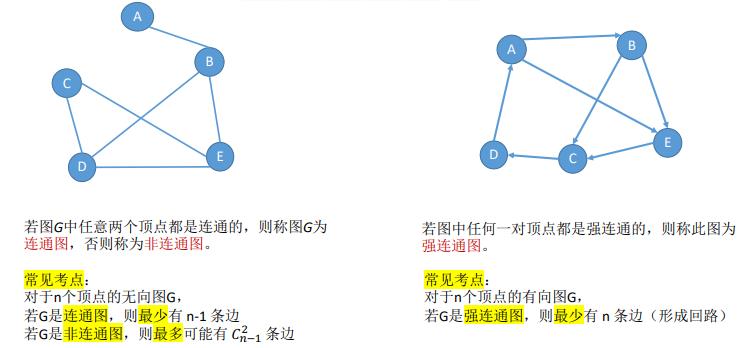
10.最小生成树
连通图的生成树是包括图中全部顶点的一个极小连通子图,若图中的顶点数维n,则它的生成树含有n-1条边,对生成树而言,若砍去它的一条边,则会变成非连通图,若加上一条边则会形成一个回路

对于一个带权连通无向图G(V,E),生成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。设R为G的所有生成树的集合,若T为R中边的权值之和最小的生成树,则T称为G的最小生成树

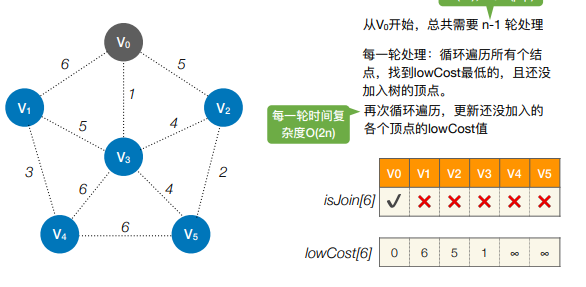
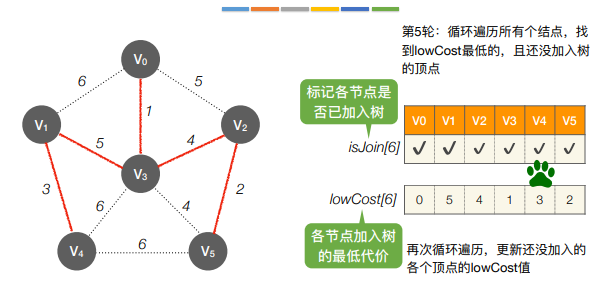
从某一个顶点开始构建生成树;每次将代价最小的新顶点纳入生成树,直到所有的顶点都纳入为止
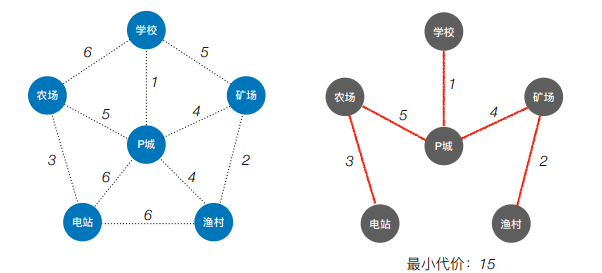
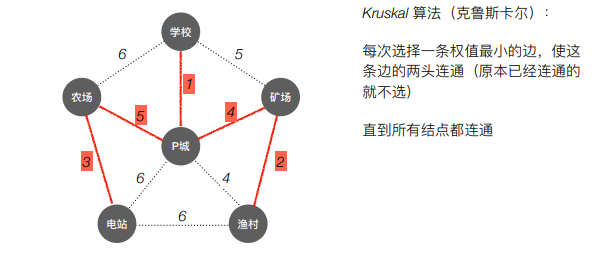
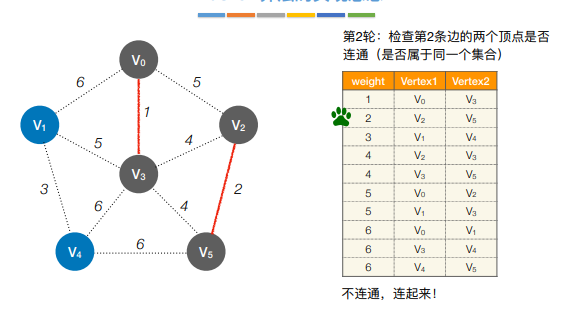
- Kruskal算法(克鲁斯卡尔)
每次选择一条权值最小的边,使这条边的两头连通(原本已经连通的不选),直到所有的结点都连通

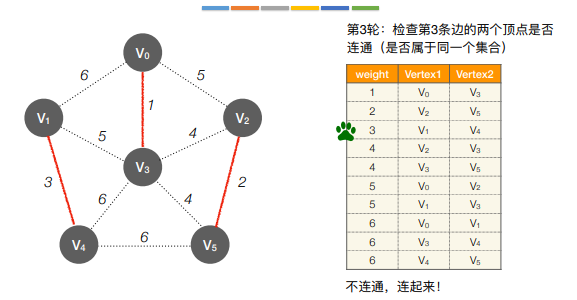
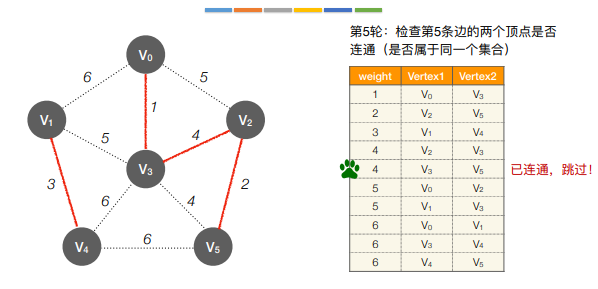
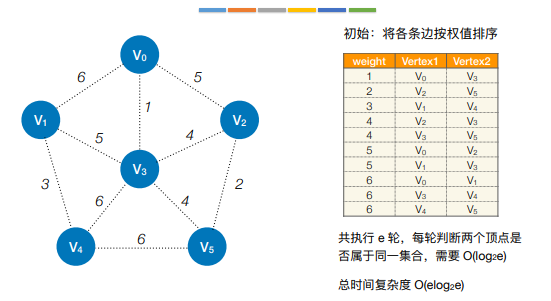

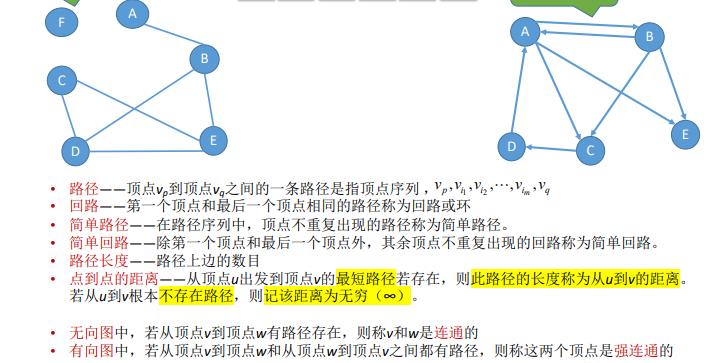
11.最短路径
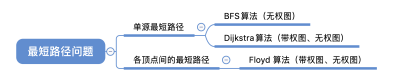
1 | |
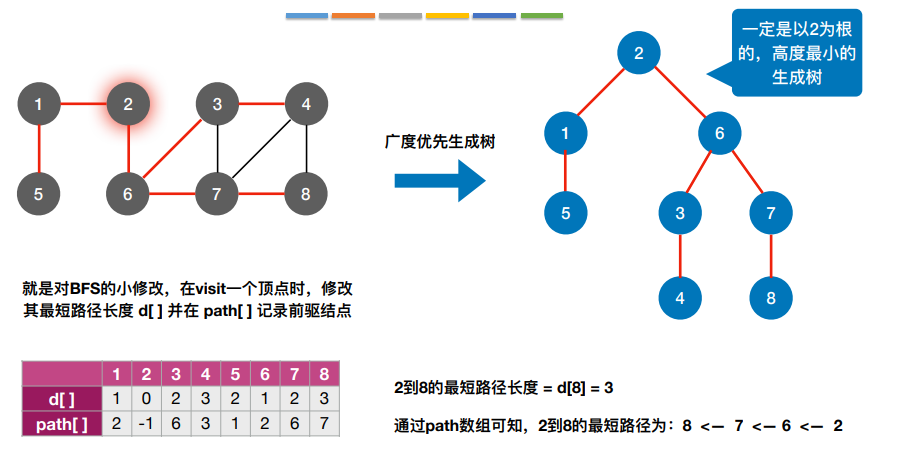
BFS算法求单源最短路径只适⽤于⽆ 权图,或所有边的权值都相同的图
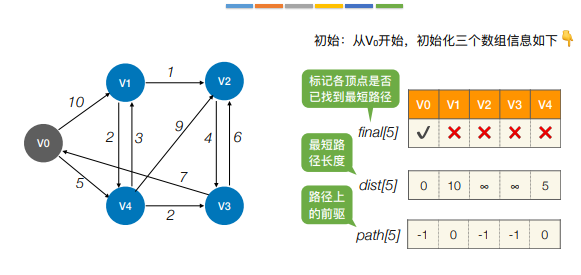

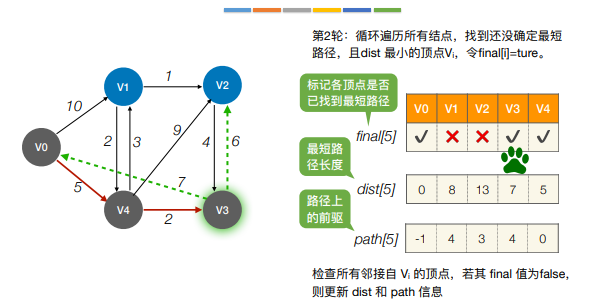
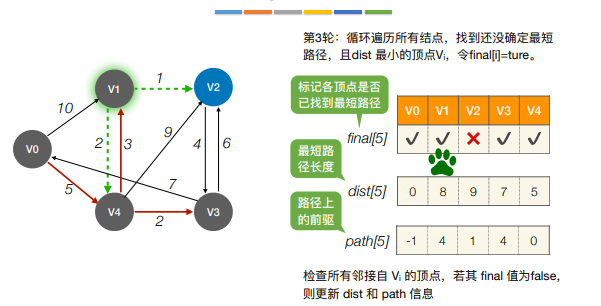
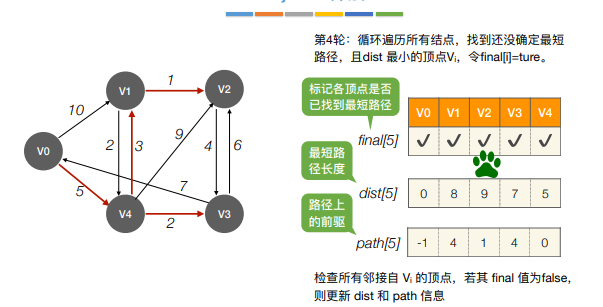

注:Dijkstra算法不适合用于有负权值的带权图
使用了动态规划思想,将问题的求解分为了多个阶段

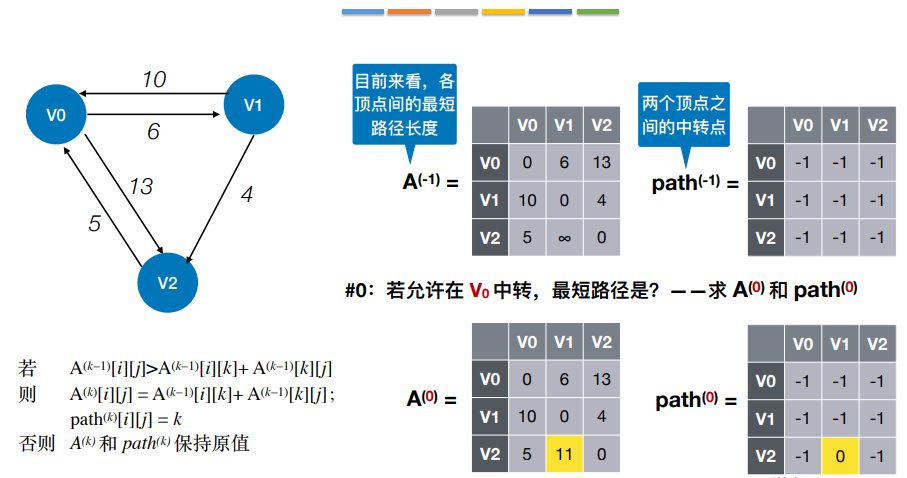
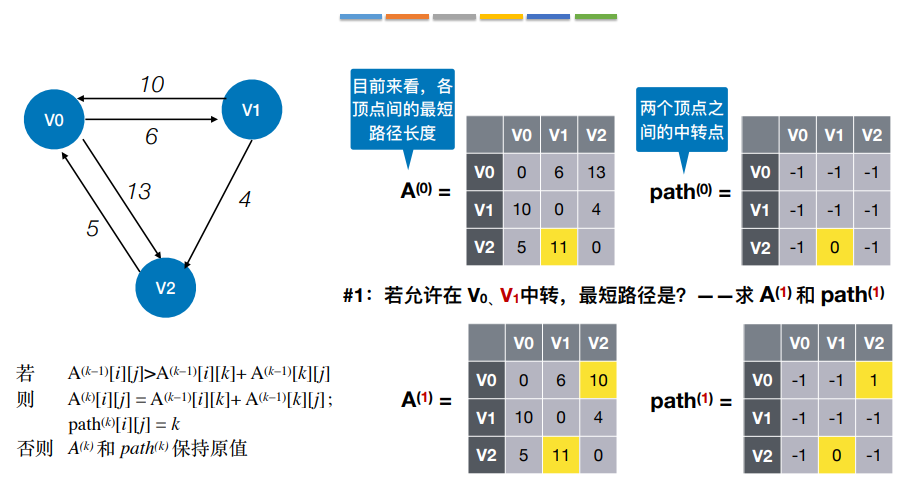


1 | |
这种算法的时间复杂度是|V|³,空间复杂度是|V|²
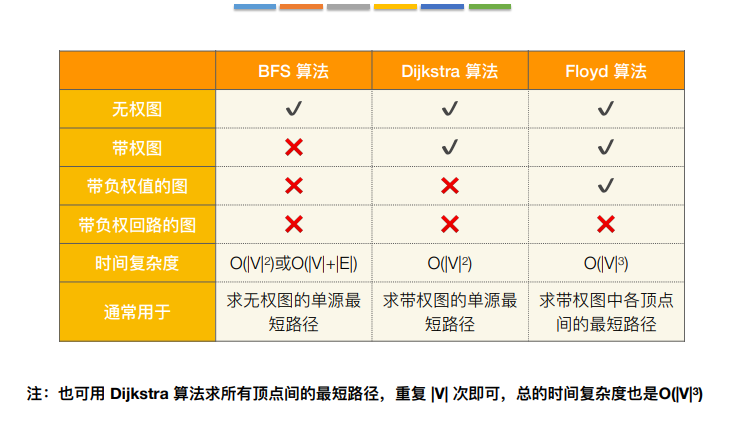
12.有向无环图(DAG)
有向⽆环图:若⼀个有向图中不存在环,则称为有向⽆环图,简称DAG图
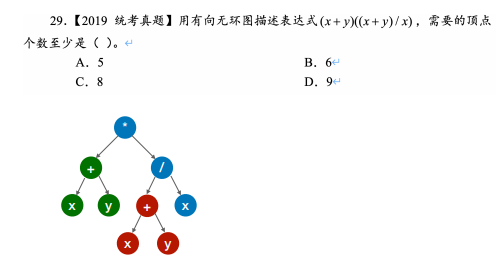
13.拓扑排序
⽤顶点表示活动的⽹,⽤DAG图(有向⽆环图)表示⼀个⼯程。顶点表示活动,有向边表示活动<Vi,Vj>,必须先于活动Vj进⾏

在图论中,由⼀个有向⽆环图 的顶点组成的序列,当且仅当满⾜下列条 件时,称为该图的⼀个拓扑排序:
① 每个顶点出现且只出现⼀次。
② 若顶点A在序列中排在顶点B的前⾯,则 在图中不存在从顶点B到顶点A的路径。


14.逆拓扑排序
对⼀个AOV⽹,如果采⽤下列步骤进⾏排序,则称之为逆拓扑排序:
① 从AOV⽹中选择⼀个没有后继(出度为0)的顶点并输出。
② 从⽹中删除该顶点和所有以它为终点的有向边。
③ 重复①和②直到当前的AOV⽹为空。

第一种方法是参考拓扑排序将入度的比较改变为出度的比较即可,第二种是利用DFS算法实现

15.关键路径
在带权有向图中,以顶点表示事件,以有向边表示活动,以边上的权值表示完成该活动的开销(如 完成活动所需的时间),称之为⽤边表示活动的⽹络,简称AOE⽹

在AOE网中仅有一个入度为0的顶点,称为开始顶点(源点),它代表整个工程的开始;也仅有一个出度为0的顶点,称为结束顶点(汇点),它代表整个工程的结束
从源点到汇点的有向路径可能有多条,所有路径中,具有最⼤路径⻓度的路径称为 关键路径,⽽把关键路径上的活动称为关键活动
决定了所有从vk开始的活动能够开⼯的最早时间

它是指在不推迟整个⼯程完成的前提下,该事件最迟必须发⽣的时间
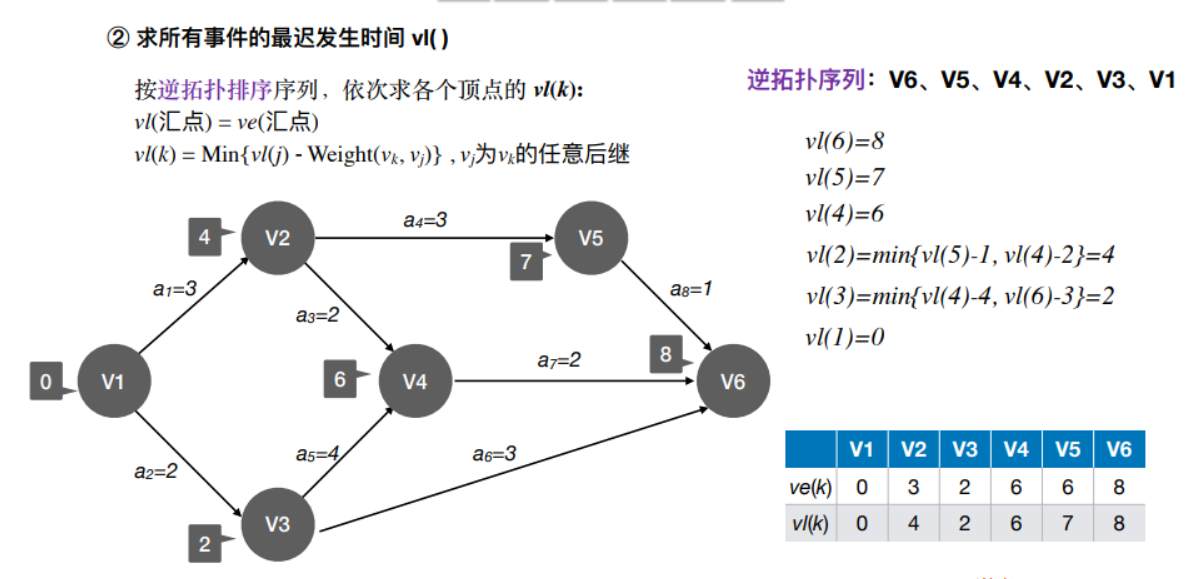
指该活动弧的起点所表⽰的事件的最早发⽣时间

它是指该活动弧的终点所表示事件的最迟发⽣时间与该活动所需时间之差
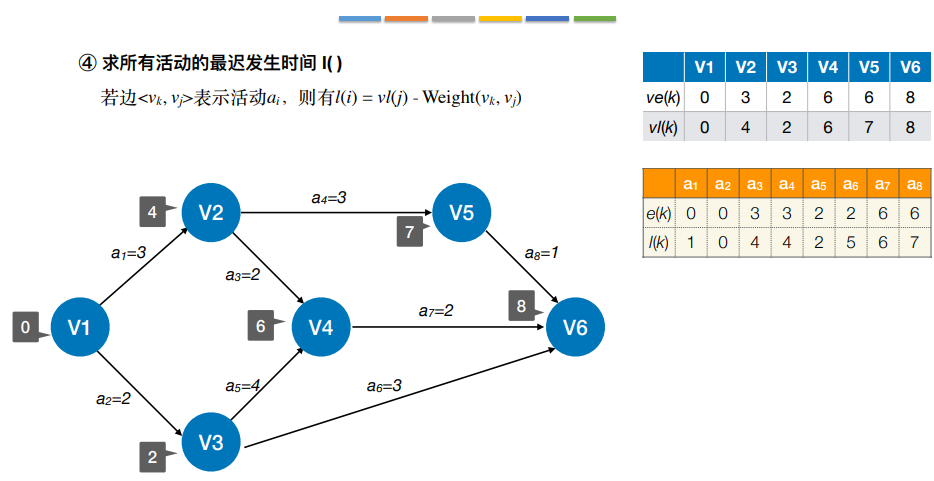
d(i)=l(i)-e(i),表⽰在不增加完成整个⼯程所需总时间的情况下,活动ai可以拖延的时间 若⼀个活动的时间余量为零,则说明该活动必须要如期完成,d(i)=0即l(i) = e(i)的活动ai是关键活动 由关键活动组成的路径就是关键路径


若关键活动耗时增加,则整个⼯程的⼯期将增⻓
缩短关键活动的时间,可以缩短整个⼯程的⼯期
当缩短到⼀定程度时,关键活动可能会变成⾮关键活动