AI–LangChain基础
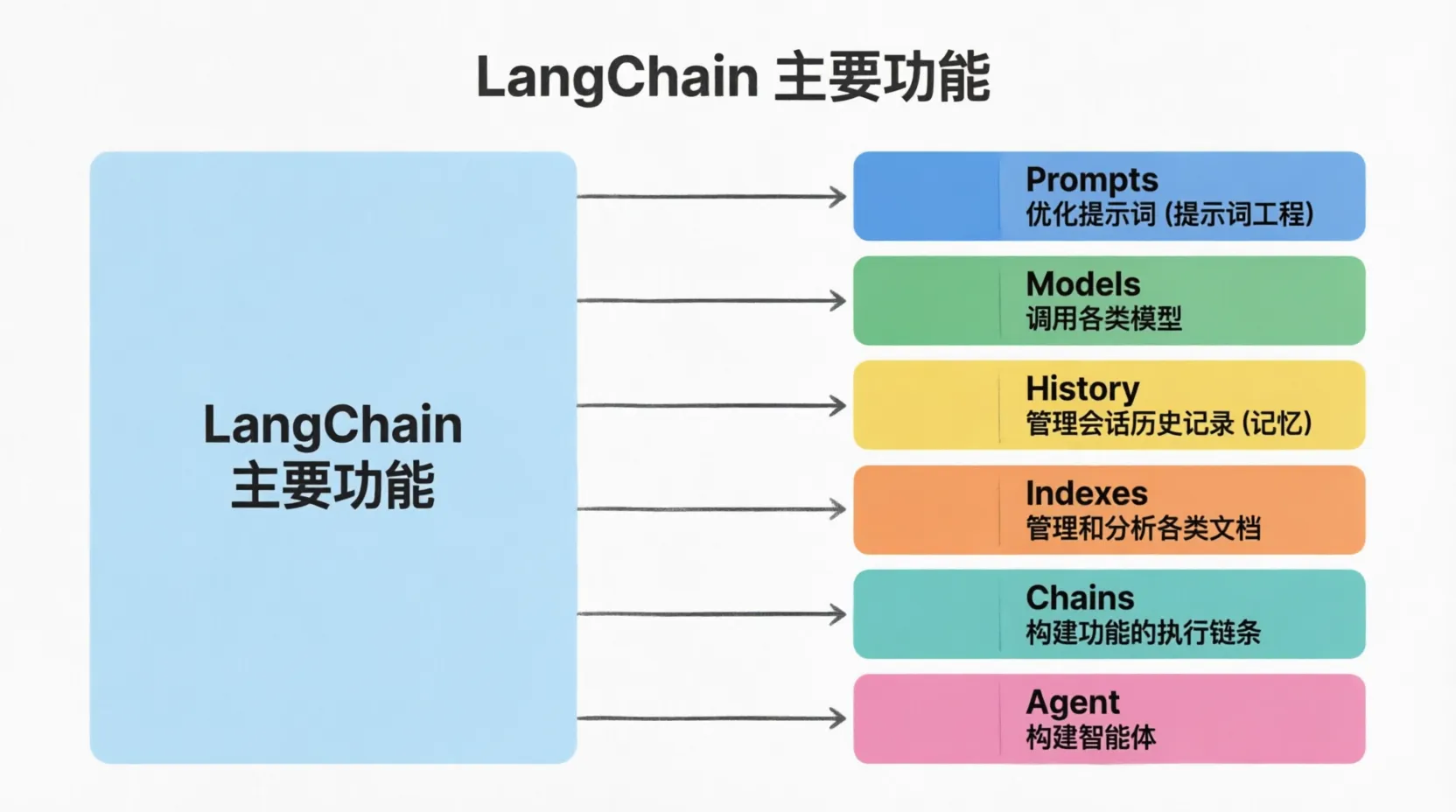
1.LangChain介绍
LangChain是于2022年10月创建,围绕LLM建立的一个框架,核心里面是为各种LLM实现通用的接口,把LLM相关的组件连接在一起,简化LLM的开发难度,方便开发者快速的开发复杂的LLM
2.LangChain的部署
LangChain在Python中已经封装成了一个库,我们可以直接调用,安装如下:
1
| pip install langchain langchain-community langchain-ollama dashscope chromadb
|
- langchain: 核心包
- langchain-community: 社区支持包,提供了更多的第三方模型调用(我们用的阿里云千问模型就需要这个包)
- langchain-ollama: Ollama支持包,支持调用Ollama托管部署的本地模型
- dashscope: 阿里云通义千问的Python SDK
- chromadb: 轻量向量数据库(后续使用)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="qwen-turbo",
api_key="key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0
)
response = llm.invoke("你好,请用一句话介绍 LangChain")
print(response.content)
|
3.LangChain的流式输出
LangChain的输出主要通过invoke和stream进行控制
- Invoke:一次性返回完整的结果
- stream:逐段返回结果,流式输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import os
from langchain_community.llms.tongyi import Tongyi
os.environ["DASHSCOPE_API_KEY"] = "KEY"
llm = Tongyi(model= "qwen-max")
response = llm.invoke("讲个冷笑话")
print(response)
for chunk in llm.stream("讲个冷笑话"):
print(chunk, end="", flush=True)
|
4.LangChain的支持模型
LangChain目前支持三种类型的模型使用:
是技术范畴的统称,指基于大参数量、海量文本训练的 Transformer 架构模型,核心能力是理解和生成自然语言,主要服务于文本生成场景
是应用范畴的细分,是专为对话场景优化的 LLMs,核心能力是模拟人类对话的轮次交互,主要服务于聊天场景
文本嵌入模型接收文本作为输入,得到文本的向量。
1
2
3
4
5
6
7
8
9
10
11
| import os
from langchain_community.llms.tongyi import Tongyi
os.environ["DASHSCOPE_API_KEY"] = "KEY"
llm = Tongyi(model= "qwen-max")
response = llm.invoke("讲个冷笑话")
print(response)
|
5.LangChain的聊天模型
所谓聊天模型,其本质其实也只是大语言模型的分支,不过我们赋予了指定模型具体所处的环境和背景,例如让他进行cosplay,也就是前面OpenAI所提到的system模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
os.environ["DASHSCOPE_API_KEY"] = "key"
chat = ChatTongyi(model="qwen-max")
messages = [
SystemMessage(content="你是一位边塞诗人"),
HumanMessage(content="写一首唐诗"),
AIMessage(content="锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content="按照你上一个回复的格式,再写一首唐诗")
]
for chunk in chat.stream(messages):
print(chunk.content, end="", flush=True)
print("-----------------")
|
除此之外,LangChain也支持简写的形式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import os
from langchain_community.chat_models.tongyi import ChatTongyi
os.environ["DASHSCOPE_API_KEY"] = "key"
chat = ChatTongyi(model="qwen-max")
messages = [
("system", "你是一位边塞诗人"),
("human", "写一首唐诗"),
("ai", "锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。"),
("human", "按照你上一个回复的格式,再写一首唐诗")
]
for chunk in chat.stream(messages):
print(chunk.content, end="", flush=True)
print("-----------------")
|
简写的好处在于可以避免导包,写起来也更加简单易懂,可以让我们在运行时填充具体的值,后续使用提示词模版时就可以用到这种方式
6.LangChain的嵌入模型
嵌入模型的特点就是将字符串作为输入,返回一个浮点数的列表(向量),在NLP中,Embedding的作用就是将数据进行文本向量化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import os
from langchain_community.embeddings import DashScopeEmbeddings
os.environ["DASHSCOPE_API_KEY"] = "key"
embeddings = DashScopeEmbeddings(model="text-embedding-v3")
result1 = embeddings.embed_query("我喜欢你")
print(result1)
result2 = embeddings.embed_documents(["我喜欢你", "我不喜欢你", "晚上吃啥"])
print(result2)
|
而在阿里云百炼平台中,所谓的向量模型也就是咱们的嵌入模型,提供了14种
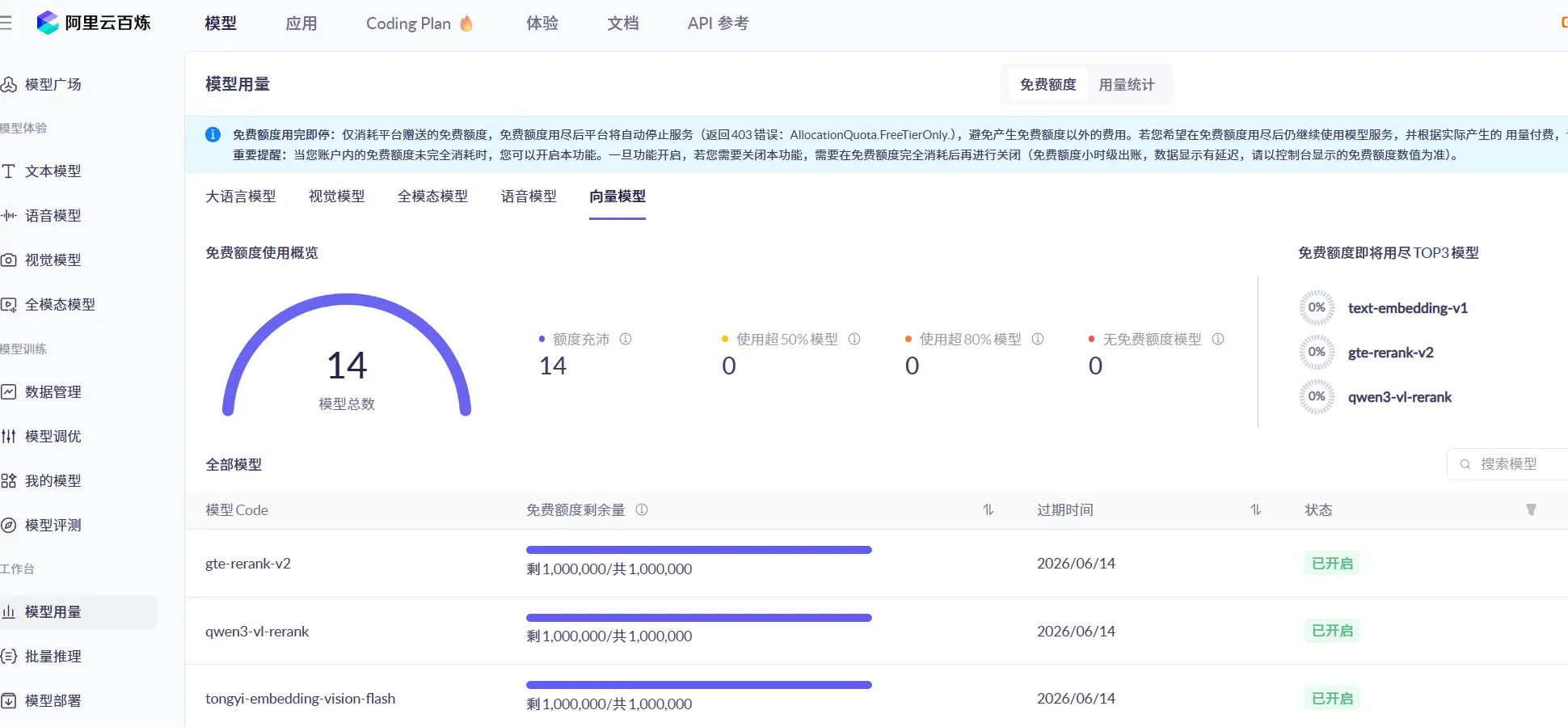
7.LangChain模型类型总结