AI–LangChain文档加载器
1.文档加载器
文档加载器提供了一套标准接口,用于将不同来源(CSV PDF JSON等)的数据读取为LangChain的文档格式,这样子确保了无论数据的来源如何,都能对其进行一致性的处理,需要实现BaseLoader接口
CLass Document是LangChain内文档的统一载体,所有文档加载器最终返回的都是此类的实例,可以看到,Document类核心记录了:
- page_content:文档内容
- metadata:文档元数据(字典)
1
2
3
4
5
6
| from langchain_core.documents import Document
document = Document(
page_content="Hello, world!",
metadata={"source": "https://example.com"}
)
|
不同的文档加载器可能定义了不同的参数,但是其都实现了统一的接口(方法)
- load():一次性加载全部文档
- lazy_load():延迟流式传输文档,对大型数据集很有用,能够避免内存溢出
1
2
3
4
5
6
7
8
9
10
11
12
| from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(
...
)
documents = loader.load()
for document in loader.lazy_load():
print(document)
|
LangChain内置了很多的文档加载器,具体详细可以参见官方文档:
1
| https://docs.langchain.com/oss/python/integrations/document_loaders
|
这里我们仅学习CSV、JSON、PDF等几个常用的文档加载器
2.CSVLoader
自定义CSV文件的解析和加载,上线我们创建一个csv文件,包含如下数据:
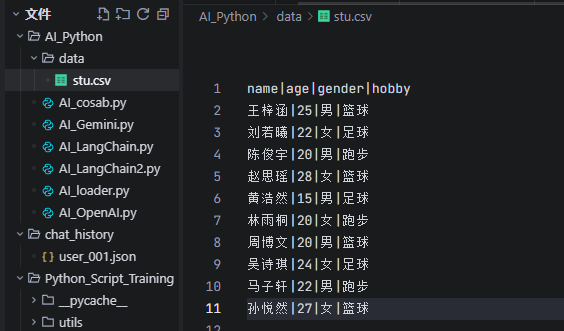
实例调用代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(
file_path="./AI_Python/data/stu.csv",
csv_args={
"delimiter": "|",
"quotechar": "'",
"fieldnames": ["name", "age", "gender", "hobby"],
},
encoding="utf-8"
)
for document in loader.lazy_load():
print(document)
|
3.JSONLoader
JSONLoader用于将JSON数据加载为Document类型对象,这里需要注意按照JSONLoader需要额外按照下jq工具,因为LangChain底层对JSON的解析就是基于jq根据实现的
现在创建一个json文件,包含如下数据:
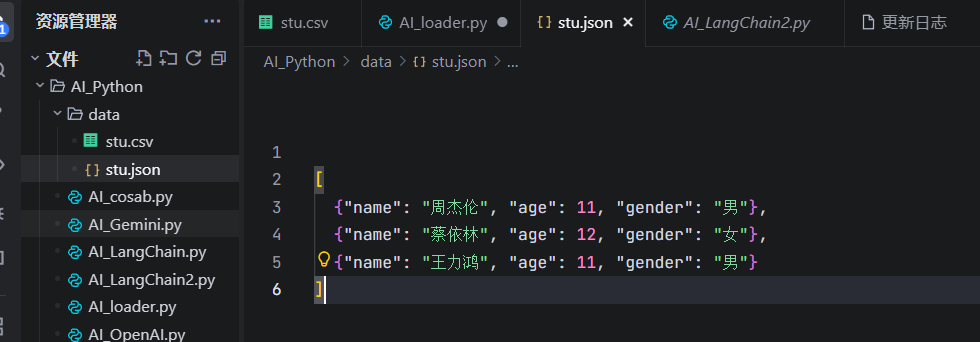
实例调用代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
| from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="./AI_Python/data/stu.json",
jq_schema=".[].name",
text_content=False,
)
docs = loader.load()
print(docs)
|
JSONLoader使用jq的解析语法,常见如:
- .表示根、[]表示数组
- .name表示从根取name的值
- .hobby[1]表示取hobby对应数组的第二个元素
- .[]表示将数组内的每个字典(JSON对象)都取到
- .[].name表示取数组内每个字典(JSON)对象的name对应的值
JSONLoader初始化有4个主要参数:
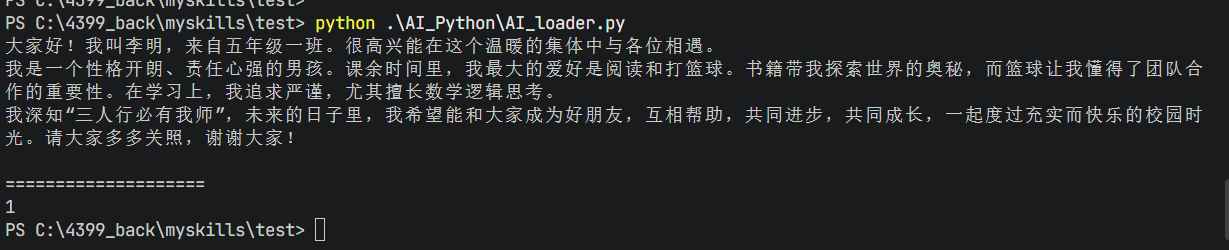
4.TextLoader
Text顾名思义就是读取文本文件(如.txt),将全部内容放入到一个Document对象中
1
2
3
4
5
6
7
8
9
10
11
| from langchain_community.document_loaders import TextLoader
loader = TextLoader(
file_path="./AI_Python/data/stu.txt",
encoding="utf-8"
)
docs = loader.load()
print(docs[0].page_content)
print("="*20)
print(len(docs))
|
但是当文档较大时,将所有内容都放到一个Document对象中就不太合适了,这里就需要用到递归字符文本分割器–RecursiveCharacterTextSplitter,作为LangChain官方推荐的默认字符分割器,主要用于按自然段落分割大文档,在报仇上下文完整性和控制片段大小之间实现了 良好的平衡
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader(
file_path="./AI_Python/data/stu.txt",
encoding="utf-8"
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=10,
length_function=len,
is_separator_regex=False,
)
splits = text_splitter.split_documents(docs)
for split in splits:
print(split.page_content)
print("="*20)
print(len(splits))
|
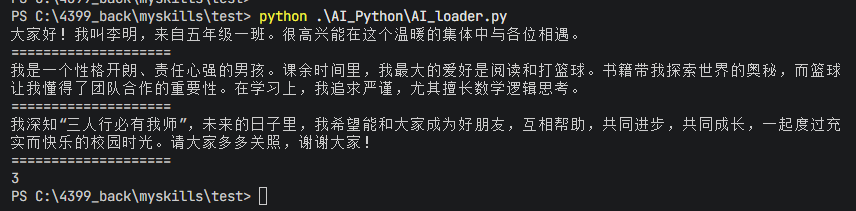
5.PyPDFLoader
LangChain内支持许多的PDF的加载器,我们选择其中的PyPDFLoader使用,和JSONLoader类似,该加载器依赖于PyPDF库,所以需要提前安装下
实例调用代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="./AI_Python/data/vpn.pdf",
mode="page"
)
i = 0
for document in loader.lazy_load():
i += 1
print(document)
print("="*20)
|