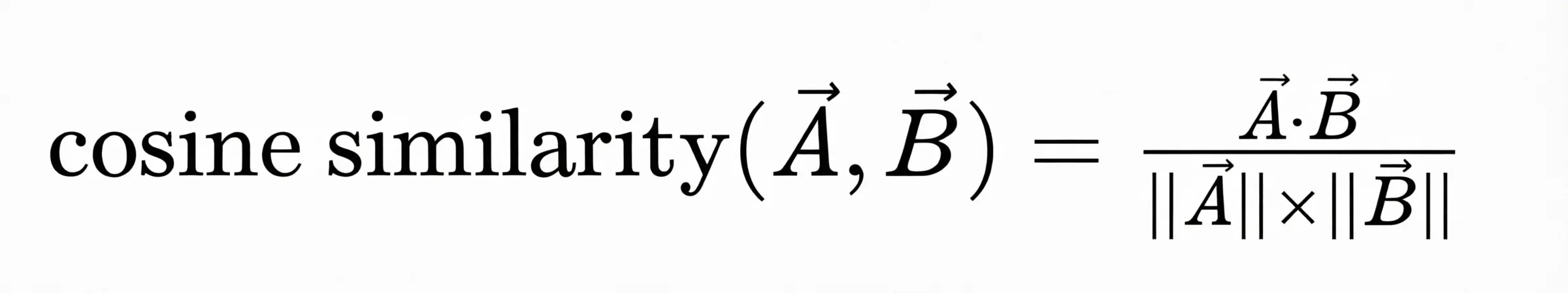AI–LangChain的向量 1.向量的概念 从前面的流程图中,涉及到了向量的相关概念,向量库是RAG中的一个重要节点
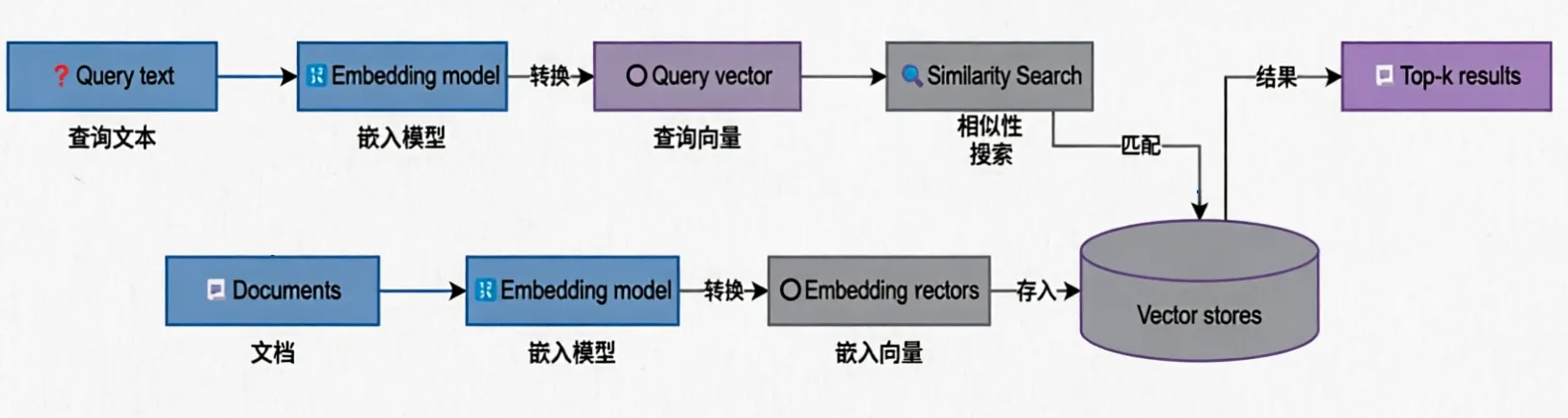
离线流程:知识和信息 -> 向量嵌入 (向量化) -> 存入向量库
在线流程:用户的提问 -> 向量嵌入 (向量化) -> 在向量库中匹配
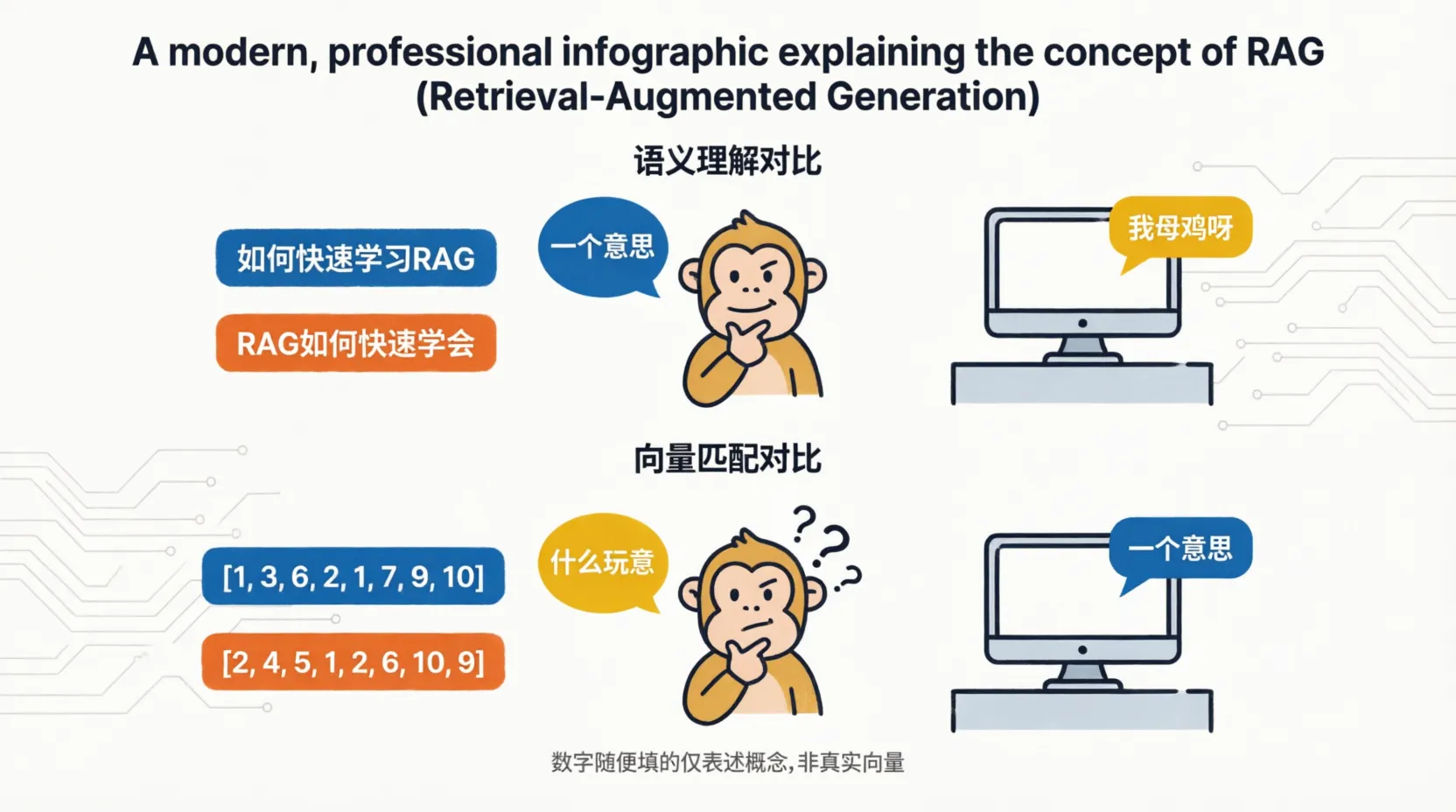
向量简单来说就是文本的数字身份证,它将一段文字的语义信息,转换成一串固定长度的数字列表,让计算机能够看懂文字的含义并做相似度计算,也就是让计算机更方便的理解不同的文本内容,是否表达的是一个意思。
向量的计算,可以接祖文本嵌入模型实现,如text-embedding-v1,其匹配通过算法实现,如余弦相似度
2.余弦相似度 在前面我们介绍了向量的概念,而在算法匹配中提到了余弦相似度,这里就简单的学习下。首先我们知道向量的数字序列,共同决定了向量在高维空间中的方向和成都,而余弦相似度主要就是在撇除长度的影响,得到方向的夹角,夹角越小则约相似,也就代表了两段文本语义更加相似。
这里只需要简单了解下即可,后续肯定是有python脚本帮助我们计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import numpy as npdef cosine_similarity (vec1, vec2 ):return dot_product / (norm_vec1 * norm_vec2)1 , 2 , 3 , 4 , 5 ])4 , 5 , 6 , 7 , 8 ])1 , -2 , -3 , -4 , -5 ])print (f"余弦相似度: {similarity} " )print (f"余弦相似度: {similarity} " )
3.向量的相关操作 在前文中有提到过文本转向量的概念,而本章节则学习向量相关的内容,典型的向量存储应用如下:
对于向量的处理主要就是存储、删除以及检索,而在LangChain总也为向量存储提供了统一的接口
存入向量:add_documents
删除向量:delete
向量检索:similarity_search
4.内部向量存储 示例文本:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from langchain_core.vectorstores import InMemoryVectorStorefrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain_community.document_loaders import CSVLoader"./AI_Python/data/xl.csv" ,"utf-8" ,"source" , "id" + str (i) for i in range (1 ,len (documents)+1 )] "id1" , "id2" ] "科学健身" , 2 print (retriever)
5.外部向量存储 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 from langchain_chroma import Chromafrom langchain_core.vectorstores import InMemoryVectorStorefrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain_community.document_loaders import CSVLoader"my_collection" , "./chroma_db" "./AI_Python/data/xl.csv" ,"utf-8" ,"source" , "id" + str (i) for i in range (1 ,len (documents)+1 )] "id1" , "id2" ] "科学健身" , 2 print (retriever)
6.基于向量检索构建提示词 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from langchain_community.chat_models import ChatTongyifrom langchain_core.vectorstores import InMemoryVectorStorefrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParser"qwen3-max" )"system" , "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。" ),"user" , "用户提问: {input}" )"text-embedding-v4" ))"减肥就是要少吃多练" , "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来" , "跑步是很好的运动哦" ])"怎么减肥?" 2 )"[" for doc in result:"]" def print_prompt (prompt ):print (prompt.to_string())print ("=" *20 )return prompt"input" : input_text, "context" : reference_text})print (res)
7.向量检索入链的优化 使用RunnablePassthrough
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 from langchain_community.chat_models import ChatTongyifrom langchain_core.vectorstores import InMemoryVectorStorefrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughfrom langchain_core.documents import Document"qwen3-max" )"system" , "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。" ),"user" , "用户提问: {input}" )"text-embedding-v4" ))"减肥就是要少吃多练" , "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来" , "跑步是很好的运动哦" ])"怎么减肥?" "k" : 2 })def format_docs (docs: list [Document] ):if not docs:return "无相关参考资料" "[" for doc in docs:"]" return formatted_str"input" : RunnablePassthrough(), "context" : retriever | format_docs} | prompt | model | StrOutputParser()print (res)""" reteriver: - 输入:用户提问 str - 输出:向量库的检索结果 list[Document] prompt: - 输入:用户提问 + 向量库的检索结果 dict - 输出:完整的提示词 PromptValue model: - 输入:完整的提示词 PromptValue - 输出:模型的回复 str """