AI--RAG介绍
AI–RAG介绍
1.RAG介绍
通用的基础大模型存在以下的一些问题:
- LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
- LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
- 幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息
- 数据安全性
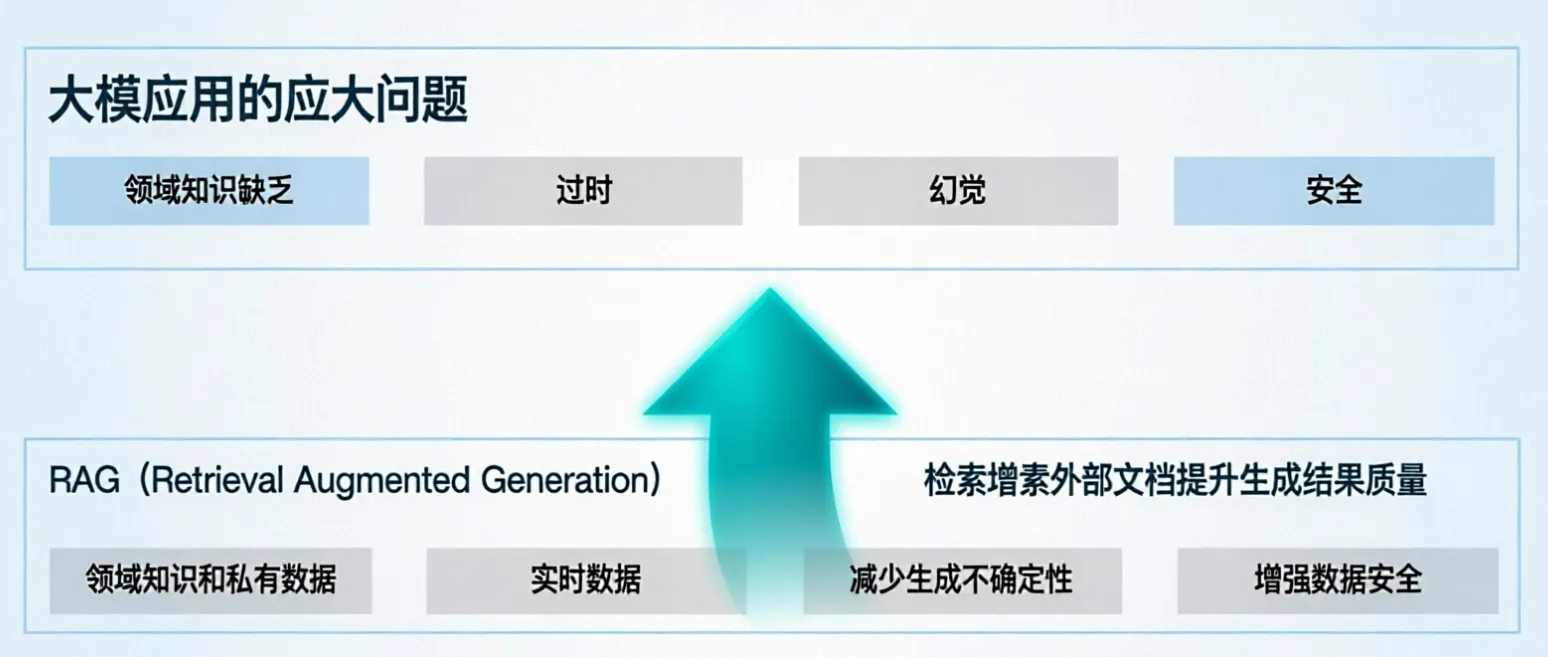
因此RAG应运而生,也就是检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案,可以理解为 RAG = 检索技术 + LLM
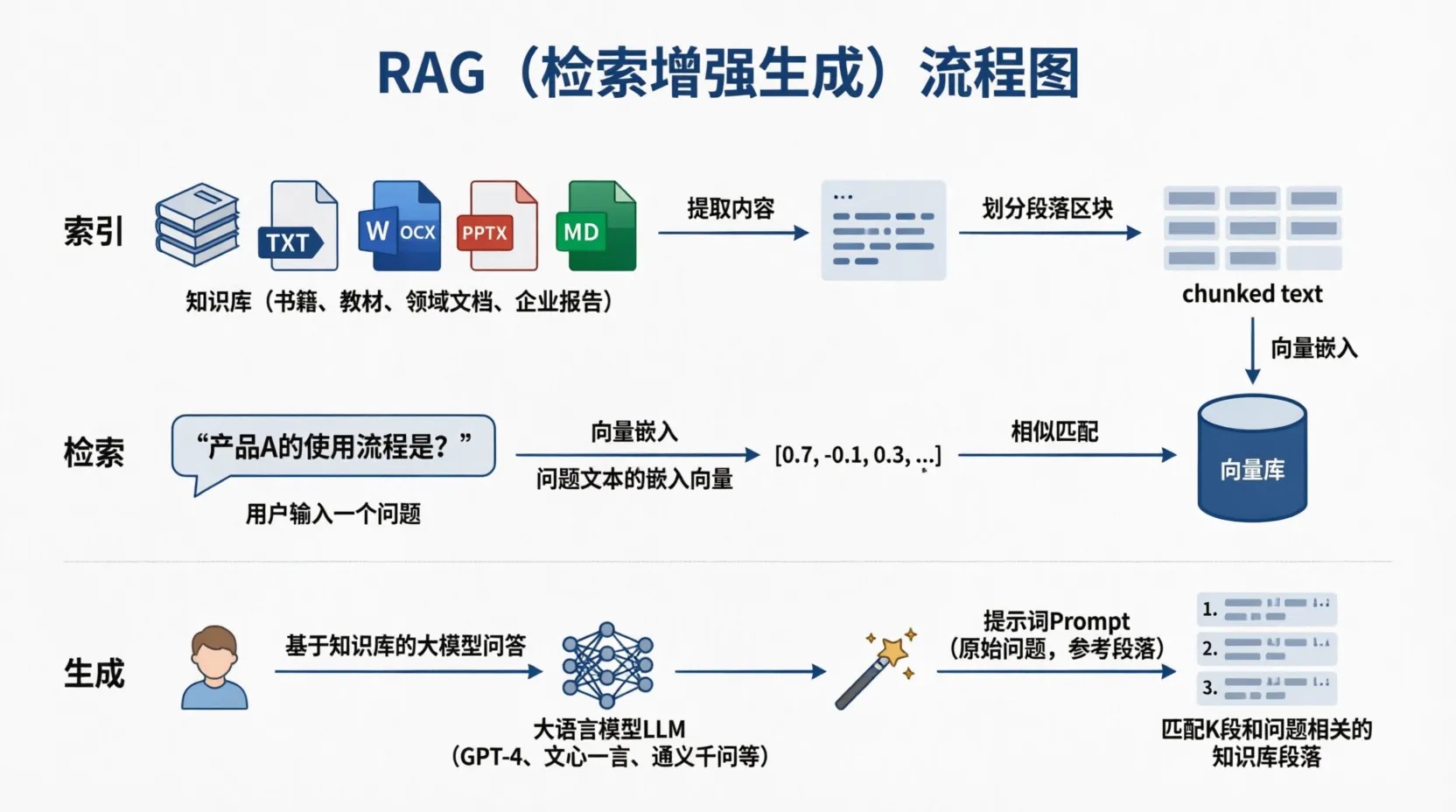
2.RAG的方向
一般而言RAG主要分为两条线,离线处理和在线处理
离线处理:想私有数据库(向量存储)源源不断添加私有知识文档
- 想知识库添加来自未来的知识库文档
- 想模型添加私有知识文档
- 给出模型参考资料,规避模型幻觉
在线处理:用户提问会先基于私有知识库做检索,获取参考资料,同步组装新提示词询问大模型获取结果

AI--RAG介绍
https://one-null-pointer.github.io/2026/02/01/AI--RAG介绍/