1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
| """
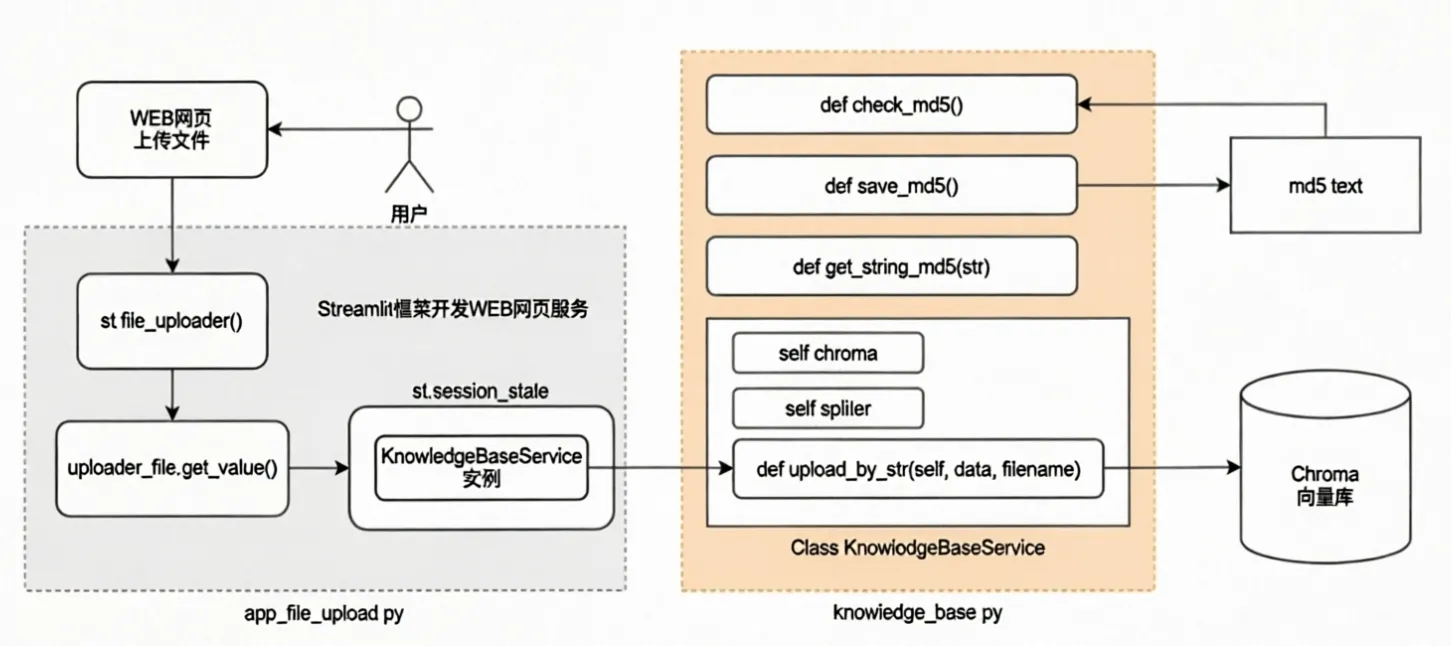
知识库
"""
from importlib import metadata
import os
import config_data as config
import hashlib
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from datetime import datetime
def check_md5(md5_str: str):
"""
检查传入的md5字符串是否已经被处理过
return False表示未处理过
True表示已处理过
"""
if not os.path.exists(config.md5_file_path):
open(config.md5_file_path, "w", encoding="utf-8").close()
return False
else:
for line in open(config.md5_file_path, "r", encoding="utf-8").readlines():
line = line.strip()
if line == md5_str:
return True
return False
def save_md5(md5_str: str):
""" 保存传入的md5字符串到文件中"""
with open(config.md5_file_path, "a", encoding="utf-8") as f:
f.write(md5_str + "\n")
def get_string_md5(input_str: str,encoding="utf-8"):
""" 将传入的字符串转换为md5字符串"""
str_bytes = input_str.encode(encoding = encoding)
md5_obj = hashlib.md5()
md5_obj.update(str_bytes)
md5_str = md5_obj.hexdigest()
return md5_str
class KnowledgeBaseService(object):
def __init__(self):
os.makedirs(config.chroma_persist_directory, exist_ok=True)
self.chroma = Chroma(
collection_name=config.chroma_collection_name,
embedding_function=DashScopeEmbeddings(model="text-embedding-v4"),
persist_directory=config.chroma_persist_directory,
)
self.spliter = RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size,
chunk_overlap=config.chunk_overlap,
separators=config.separators,
length_function=len,
)
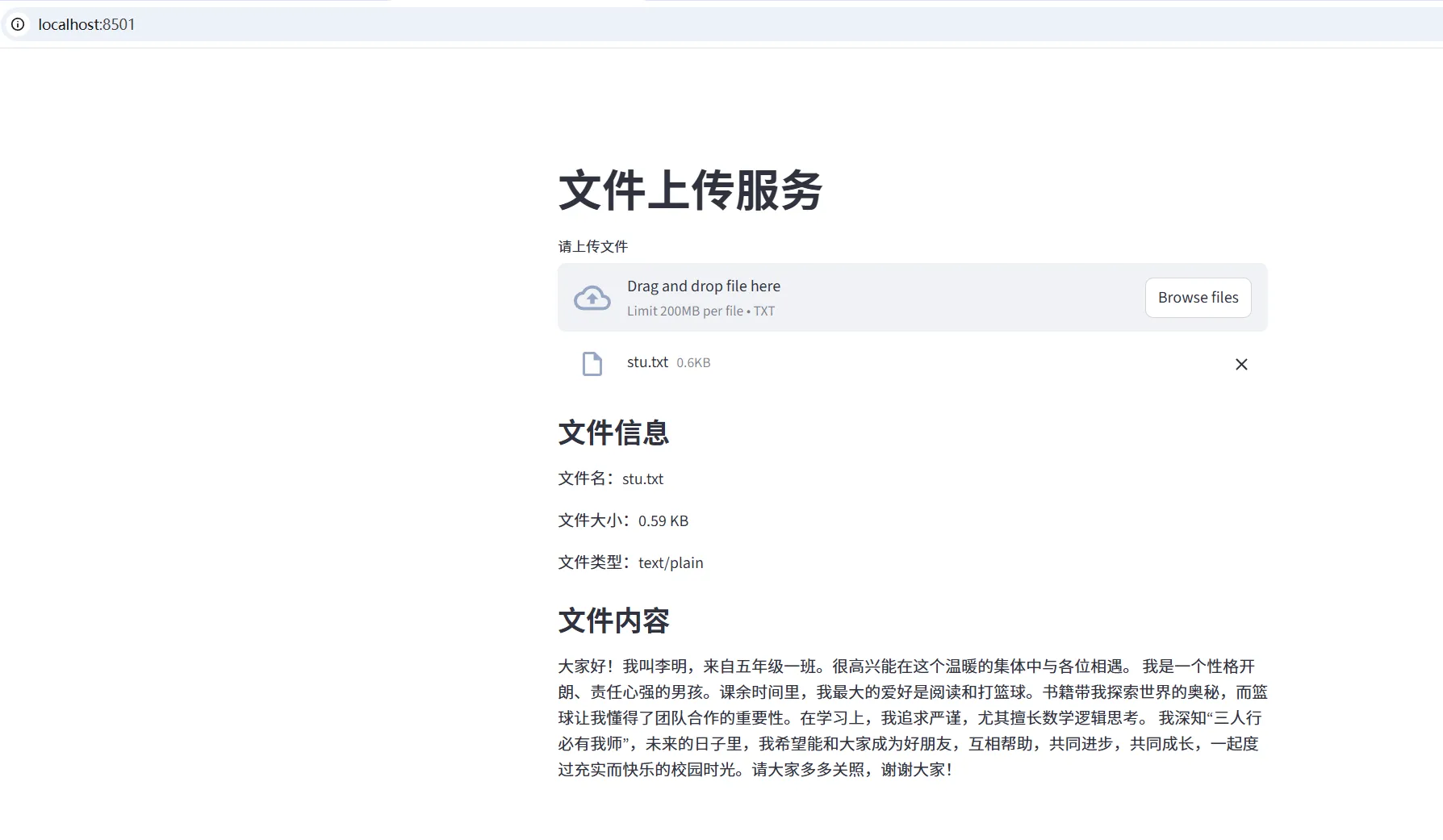
def upload_file(self, data, file_name) :
""" 将出入的字符串,进行向量化,存入向量数据库中"""
md5_str = get_string_md5(data)
if check_md5(md5_str):
return "[跳过]内容已经存在知识库中了"
if len(data) > config.max_splist_chat_number:
knowledge_chunks : list[str] = self.spliter.split_text(data)
else:
knowledge_chunks = [data]
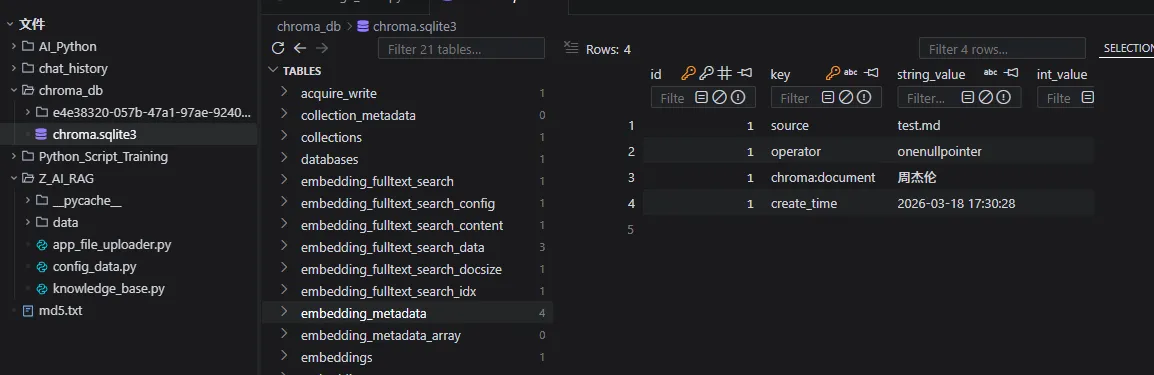
metadata = {
"source": file_name,
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"operator": "onenullpointer",
}
self.chroma.add_texts(
knowledge_chunks,
metadatas=[metadata for _ in knowledge_chunks]
)
save_md5(md5_str)
return "[成功]内容已加载到知识库中"
if __name__ == "__main__":
kb_service = KnowledgeBaseService()
kb_service.upload_file("周杰伦", "test.md")
|