RAG–文本分块 0.前言 前面我们提到了在RAG的流程中首先是需要进行分块,基于LLM上下文长度的限制以及西凉检索对语义完整性的依赖,如何进行高质量文本分块就成为了一个首要问题。
1.理想的分块标准
用chunk_size控制大小(一般是256/512/1024的token或字符),chunk_overlap保连续(10%-20% of chunk_size)
2.分块策略 2.1 基础分块
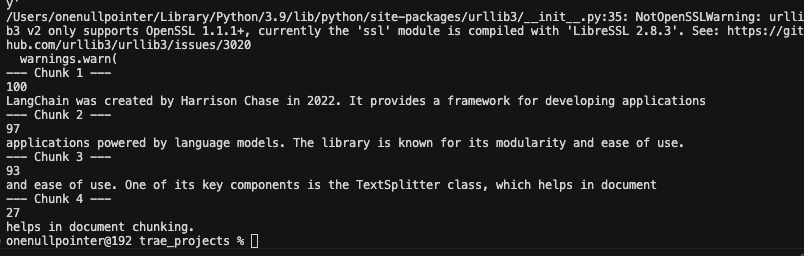
按照固定字数切割文本,不考虑语义结构,优点是实现简单,但是容易破坏句子完整性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain_text_splitters import CharacterTextSplitter"LangChain was created by Harrison Chase in 2022. It provides a framework for developing applications " "powered by language models. The library is known for its modularity and ease of use. " "One of its key components is the TextSplitter class, which helps in document chunking." " " , 100 , 20 , len , for i, doc in enumerate (docs):print (f"--- Chunk {i + 1 } ---" )print (len (doc.page_content))print (doc.page_content)
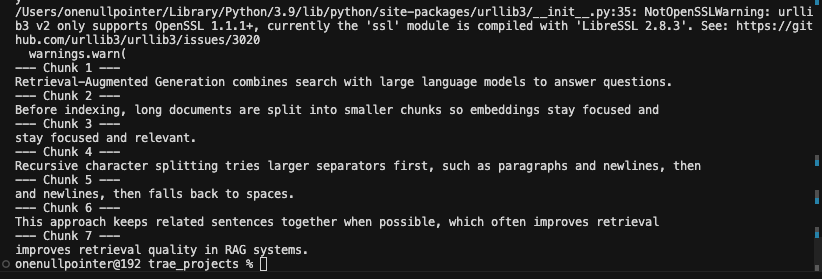
核心思想是按照优先级分隔符递归切分”\n\n” -> “\n”, “ -> “, “”,从而尽可能的保留段落和句子完整性,适用于绝大多数通用文本的首选策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from langchain_text_splitters import RecursiveCharacterTextSplitter"Retrieval-Augmented Generation combines search with large language models to answer questions.\n\n" "Before indexing, long documents are split into smaller chunks so embeddings stay focused and relevant.\n" "Recursive character splitting tries larger separators first, such as paragraphs and newlines, then falls back to spaces.\n" "This approach keeps related sentences together when possible, which often improves retrieval quality in RAG systems." 100 , 20 , for i, doc in enumerate (docs):print (f"--- Chunk {i + 1 } ---" )print (doc.page_content)
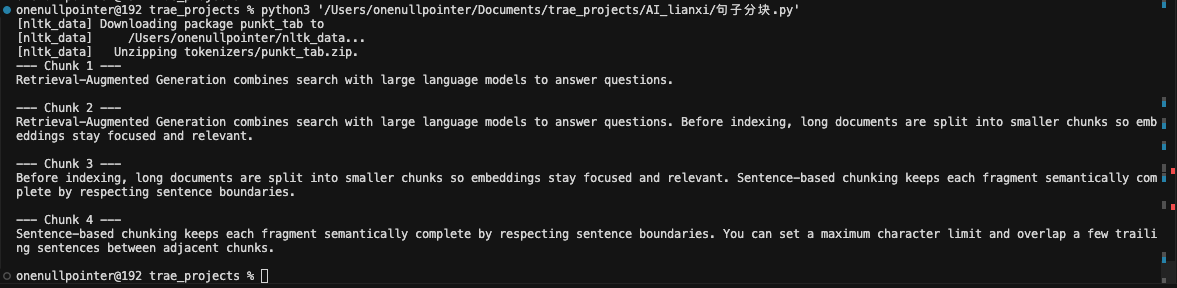
核心思路是以完整的句子为单位进行组合,确保语义的完整,适用于法律文书、新闻报道、对句子完整性要求高的领域
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 """ 基于句子的 RAG 文本分块。 英文:使用 NLTK 的 sent_tokenize(需 punkt 模型)。 中文:NLTK 对中文支持很差,改用按中文标点(。!?;)的正则分句。 """ import reimport nltkfrom nltk.tokenize import sent_tokenizetry :"tokenizers/punkt_tab" )except LookupError:"punkt_tab" )def _has_chinese (text: str ) -> bool :"""判断文本是否包含中文字符。""" return bool (re.search(r"[\u4e00-\u9fff]" , text))def split_sentences (text: str , language: str = "auto" ) -> list [str ]:""" 将文本切分为句子列表。 Args: text: 待分句文本 language: "auto" 自动检测 | "english" | "chinese" """ if language == "auto" :"chinese" if _has_chinese(text) else "english" if language == "chinese" :r"(?<=[。!?;\n])" , text)return [p.strip() for p in parts if p.strip()]return sent_tokenize(text)def chunk_by_sentences ( text: str , max_chars: int = 500 , overlap_sentences: int = 1 , language: str = "auto" , """ 按句子合并为多个 chunk,每块不超过 max_chars 字符。 Args: text: 待分块全文 max_chars: 单块最大字符数 overlap_sentences: 相邻块重叠的句子数(保留上下文) language: 分句语言,见 split_sentences """ "" if (language == "chinese" or (language == "auto" and _has_chinese(text))) else " " "" for i, sentence in enumerate (sentences):f"{current_chunk} {sep} {sentence} " .strip() if current_chunk else sentenceif len (candidate) <= max_chars:else :if current_chunk:max (0 , i - overlap_sentences)1 ])if current_chunk.strip():return chunks"Retrieval-Augmented Generation combines search with large language models to answer questions. " "Before indexing, long documents are split into smaller chunks so embeddings stay focused and relevant. " "Sentence-based chunking keeps each fragment semantically complete by respecting sentence boundaries. " "You can set a maximum character limit and overlap a few trailing sentences between adjacent chunks." 100 , overlap_sentences=1 , language="auto" )for i, chunk in enumerate (chunks):print (f"--- Chunk {i + 1 } ---" )print (chunk)print ()
2.2结构感知
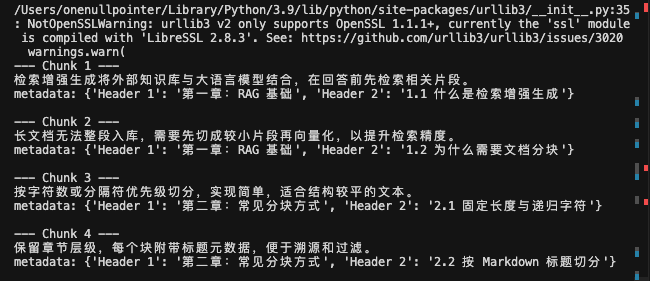
很多技术文档是按照标题层级划分,通过按照标题层级切分,自动保留元数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from langchain_text_splitters import MarkdownHeaderTextSplitter""" # 第一章:RAG 基础 ## 1.1 什么是检索增强生成 检索增强生成将外部知识库与大语言模型结合,在回答前先检索相关片段。 ## 1.2 为什么需要文档分块 长文档无法整段入库,需要先切成较小片段再向量化,以提升检索精度。 # 第二章:常见分块方式 ## 2.1 固定长度与递归字符 按字符数或分隔符优先级切分,实现简单,适合结构较平的文本。 ## 2.2 按 Markdown 标题切分 保留章节层级,每个块附带标题元数据,便于溯源和过滤。 """ "#" , "Header 1" ),"##" , "Header 2" ),for i, split in enumerate (md_header_splits):print (f"--- Chunk {i + 1 } ---" )print (split.page_content)print ("metadata:" , split.metadata)print ()
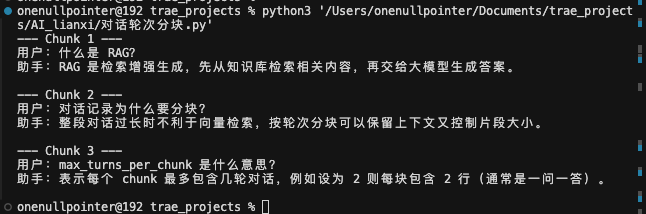
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 """ 对话轮次分块:按轮次将多轮对话切成多个 chunk,适合客服记录、聊天记录等 RAG 场景。 """ def chunk_dialogue (dialogue_lines, max_turns_per_chunk=2 ):""" 将对话列表按轮次分组。 Args: dialogue_lines: 每行一轮,如 "用户:..." / "助手:..." max_turns_per_chunk: 每个 chunk 包含的最大轮次数 """ for i in range (0 , len (dialogue_lines), max_turns_per_chunk):"\n" .join(dialogue_lines[i : i + max_turns_per_chunk])return chunks"用户:什么是 RAG?" ,"助手:RAG 是检索增强生成,先从知识库检索相关内容,再交给大模型生成答案。" ,"用户:对话记录为什么要分块?" ,"助手:整段对话过长时不利于向量检索,按轮次分块可以保留上下文又控制片段大小。" ,"用户:max_turns_per_chunk 是什么意思?" ,"助手:表示每个 chunk 最多包含几轮对话,例如设为 2 则每块包含 2 行(通常是一问一答)。" ,2 )for i, chunk in enumerate (chunks):print (f"--- Chunk {i + 1 } ---" )print (chunk)print ()
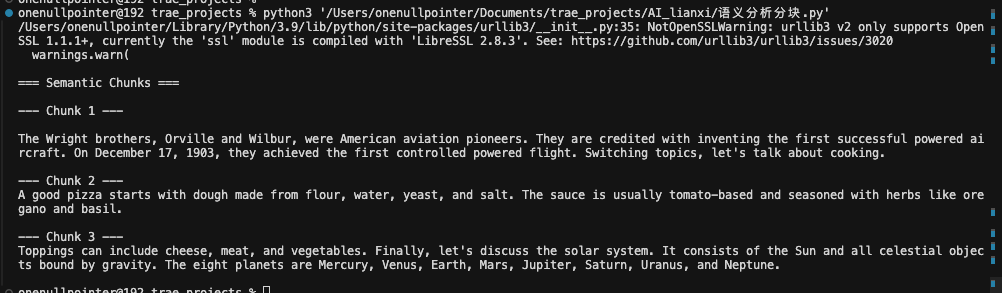
2.3语义分块 在langchain当中提供了语义分块(Semantic Chunking),原理是计算句向量相似度,在语义突变处进行切分,工具是langchain_experimental.SemanticChunker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import osfrom langchain_experimental.text_splitter import SemanticChunkerfrom langchain_huggingface import HuggingFaceEmbeddings"TOKENIZERS_PARALLELISM" ] = "false" """ The Wright brothers, Orville and Wilbur, were American aviation pioneers. They are credited with inventing the first successful powered aircraft. On December 17, 1903, they achieved the first controlled powered flight. Switching topics, let's talk about cooking. A good pizza starts with dough made from flour, water, yeast, and salt. The sauce is usually tomato-based and seasoned with herbs like oregano and basil. Toppings can include cheese, meat, and vegetables. Finally, let's discuss the solar system. It consists of the Sun and all celestial objects bound by gravity. The eight planets are Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, and Neptune. """ "BAAI/bge-large-en-v1.5" ,"device" : "cpu" },"normalize_embeddings" : True }"percentile" ,80 ,print ("\n=== Semantic Chunks ===\n" )for i, doc in enumerate (docs):print (f"--- Chunk {i+1 } ---" )print (doc.page_content)print ()
2.4 主题分块 比较适合长文本,但是不稳定,需要大量的调参
(用的比较少,基本不太适合生产环境,这里不过多进行学习)
2.5 高级策略
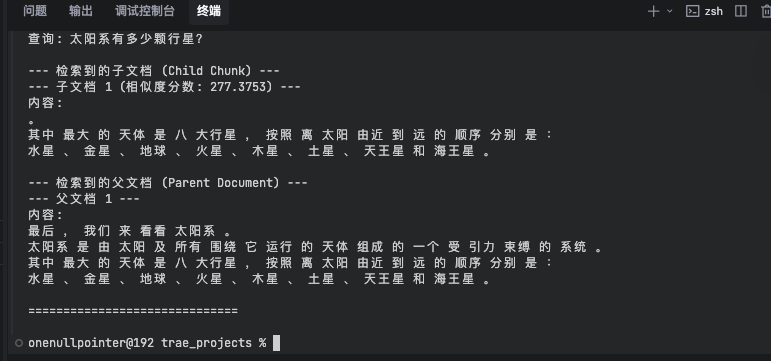
结合小块检索的高精度和大块生成的高上下文优势,检索时使用细粒度的小块确保相关性,生成回答时则将其对应的大块父文档作为上下文,提供更丰富的信息,核心工具是ParentDocumentRetriever
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 import osimport jiebafrom typing import List from langchain_chroma import Chromafrom langchain_huggingface import HuggingFaceEmbeddingsfrom langchain.retrievers import ParentDocumentRetrieverfrom langchain.storage import InMemoryStorefrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_core.documents import Document"TOKENIZERS_PARALLELISM" ] = "false" "HF_ENDPOINT" ] = "https://hf-mirror.com" def chinese_word_segmentation (text: str ) -> str :""" 使用 jieba 对中文文本进行分词,并用空格连接。 Args: text (str): 待分词的中文文本。 Returns: str: 分词后用空格连接的文本。 """ for line in text.splitlines():if line.strip():" " .join(jieba.cut(line)))else :"" ) return "\n" .join(segmented_lines)if __name__ == "__main__" :"莱特兄弟——奥维尔(Orville)和威尔伯(Wilbur)——是两位美国航空先驱,通常被认为发明并驾驶了世界上第一架成功的动力飞机。\n" "1903年12月17日,他们在基蒂霍克(Kitty Hawk)附近完成了首次可控、持续的飞行。\n" "在接下来的几年里,他们继续改进自己的飞机设计。\n\n" "完全换个话题,我们来聊聊烹饪。\n" "一个好的披萨始于完美的面团,而面团需要酵母、面粉、水和盐。\n" "酱料通常以番茄为基础,并加入牛至和罗勒等香草调味。\n" "配料则可以从简单的马苏里拉奶酪到各种肉类和蔬菜。\n\n" "最后,我们来看看太阳系。\n" "太阳系是由太阳及所有围绕它运行的天体组成的一个受引力束缚的系统。\n" "其中最大的天体是八大行星,按照离太阳由近到远的顺序分别是:\n" "水星、金星、地球、火星、木星、土星、天王星和海王星。" print ("--- 原始文本 ---" )print (raw_text)print ("\n" + "=" *30 + "\n" )print ("--- 分词预处理后的文本 ---" )print (preprocessed_text)print ("\n" + "=" *30 + "\n" )"shibing624/text2vec-base-chinese" 300 , 0 ,"\n\n" , "\n" , "。" , "!" , "?" , "\s" ], len ,False ,100 , 0 ,"。" , "!" , "?" , "\n\n" , "\n" , "\s" ], len ,False ,"parent_document_chunks" , embedding_function=embeddings)"k" : 1 } print ("--- 文档添加完成,开始检索示例 ---" )print ("\n" + "=" *30 + "\n" )"飞机是如何发明的?" ,"披萨的配料有哪些?" ,"太阳系有多少颗行星?" for query in queries:print (f"查询: {query} \n" )1 )if child_docs_with_score:print ("--- 检索到的子文档 (Child Chunk) ---" )for i, (child_doc, score) in enumerate (child_docs_with_score):print (f"--- 子文档 {i + 1 } (相似度分数: {score:.4 f} ) ---" )print (f"内容:\n{child_doc.page_content} " )print ()else :print ("--- 未检索到子文档 ---" )print ()print ("--- 检索到的父文档 (Parent Document) ---" )if retrieved_parent_docs:for i, parent_doc in enumerate (retrieved_parent_docs):print (f"--- 父文档 {i + 1 } ---" )print (f"内容:\n{parent_doc.page_content} " )print ()else :print ("--- 未检索到父文档 ---" )print ()print ("=" *30 + "\n" )
赋予LLM判断能力,使其能够像人类专家一样,根据问题动态识别文档中的“知识单元”。这种方法能够产生极高质量的分块,但是计算成本也最高,只适用于高价值小规模的知识库体系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import textwrapfrom typing import List from langchain_openai import ChatOpenAIfrom langchain.prompts import PromptTemplatefrom langchain_core.output_parsers import PydanticOutputParserfrom pydantic import BaseModel, Fieldclass KnowledgeChunk (BaseModel ):str = Field(description="简洁明了的标题" )str = Field(description="自包含的文本内容" )str = Field(description="该知识块可回答的典型问题" )class ChunkList (BaseModel ):List [KnowledgeChunk]""" 【角色】: 你是一位顶尖的科学文档分析师,你的任务是将复杂的科学文本段落,分解成一组核心的、自包含的“知识块(Knowledge Chunk)”。 【核心任务】: 阅读用户提供的文本段落,识别其中包含的独立的知识概念。 【规则】: 1. **自包含性**: 每个“知识块”必须是“自包含的(self-contained)”。 2. **概念单一性**: 每个“知识块”应该只围绕一个核心概念。 3. **提取并重组**: 从原文中提取与该核心概念相关的所有句子,并将它们组合成一个通顺、连贯的段落。 4. **遵循格式**: 严格按照下面的JSON格式指令来构建你的输出。 {format_instructions} 【待处理文本】: {paragraph_text} """ "paragraph_text" ],"format_instructions" : parser.get_format_instructions()},if __name__ == "__main__" :"莱特兄弟——奥维尔(Orville)和威尔伯(Wilbur)——是两位美国航空先驱,通常被认为发明并驾驶了世界上第一架成功的动力飞机。 " "1903年12月17日,他们在基蒂霍克(Kitty Hawk)附近完成了首次可控、持续的飞行。 " "在接下来的几年里,他们继续改进自己的飞机设计。 " "完全换个话题,我们来聊聊烹饪。 " "一个好的披萨始于完美的面团,而面团需要酵母、面粉、水和盐。 " "酱料通常以番茄为基础,并加入牛至和罗勒等香草调味。 " "配料则可以从简单的马苏里拉奶酪到各种肉类和蔬菜。 " "最后,我们来看看太阳系。 " "太阳系是由太阳及所有围绕它运行的天体组成的一个受引力束缚的系统。 " "其中最大的天体是八大行星,按照离太阳由近到远的顺序分别是: " "水星、金星、地球、火星、木星、土星、天王星和海王星。" 0 , model_name="gpt-3.5-turbo" )print ("\n--- 发送给LLM的完整提示词 ---\n" )print (formatted_prompt.to_string())print ("\n----------------------------------\n" )print ("\n--- 知识块分块结果 ---\n" )for i, chunk in enumerate (parsed_output.chunks):print (f"--- 知识块 {i + 1 } ---" )print (f"标题: {chunk.chunk_title} " )print (f"内容: {textwrap.fill(chunk.chunk_text, width=80 )} " )print (f"典型问题: {chunk.representative_question} " )print ()
2.6 混合模块–复杂文档的最佳实践 策略:先结构粗切-》再语义/递归细切,适用于技术白皮书、年报、多格式混合文档等,适合处理包含多种元素(文本、图表、代码)或者逻辑层次比较复杂的长文档
3.决策框架
结构化文档(如PDF、Markdown)?对话记录?还是无格式纯文本?
追求高精度的检索效果?还是需要支持长上下文的生成任务?
是否能够承受LLM语义分块带来的计算开销和延迟?
4.建议 1 2 3 4 5 6 7 8 9 10 11 12 13 优先RecursiveCharacterTextSplitterpercentile =70 开始调