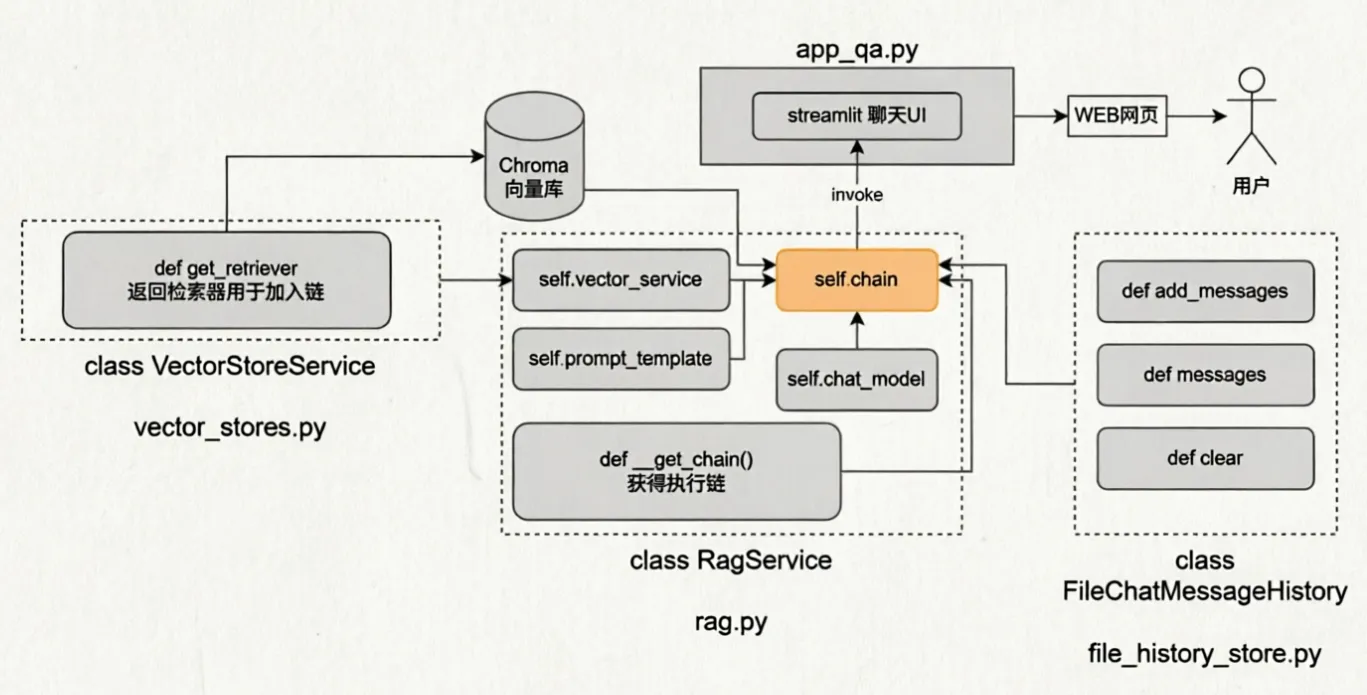
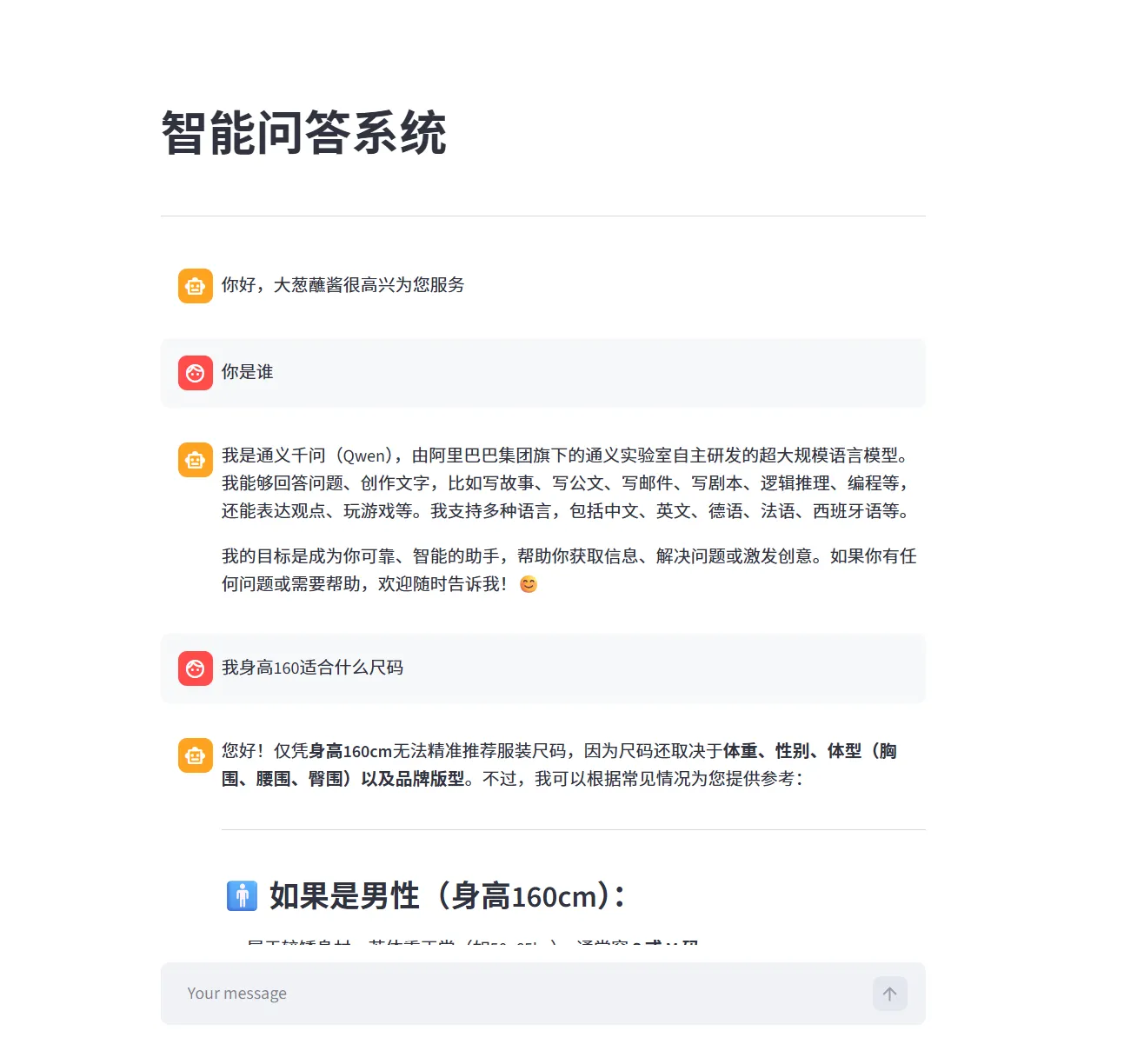
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage, message_to_dict, messages_from_dict
import json
import os
from typing import Sequence
def get_history(session_id):
return FileChatMessageHistory(session_id, "./Z_AI_RAG/chat_history")
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.session_id = session_id
self.storage_path = storage_path
self.file_path = os.path.join(self.storage_path, f"{self.session_id}.json")
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, message: Sequence[BaseMessage]) -> None:
all_messages = list(self.messages)
all_messages.extend(message)
new_messages = [message_to_dict(message) for message in all_messages]
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f)
@property
def messages(self) -> list[BaseMessage]:
try:
with open(self.file_path, "r", encoding="utf-8") as f:
message_data = json.load(f)
return messages_from_dict(message_data)
except FileNotFoundError:
return []
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f)
|