AI–智能体ReAct架构 0.前言 现在已经有了LLM客户端,接下来我们将构造第一个智能体范式ReAct。
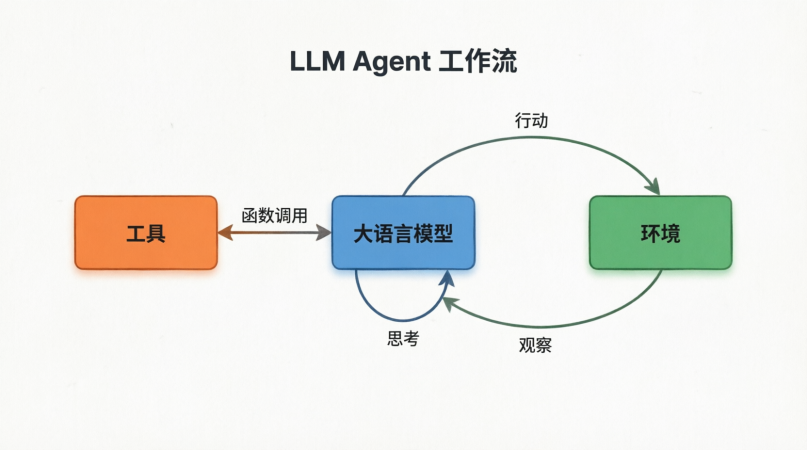
1.ReAct的工作流程 ReAct的宗旨是认为思考与行动是相辅相成的,思考指导行动,而行动又会发过来修正思考,因此,该范式通过一种特殊的提示工程来引导模型,使得每一步的输出都遵循一个固定的轨迹:
Thought (思考): 这是智能体的“内心独白”。它会分析当前情况、分解任务、制定下一步计划,或者反思上一步的结果。Action (行动): 这是智能体决定采取的具体动作,通常是调用一个外部工具.。Observation (观察): 这是执行Action后从外部工具返回的结果,例如搜索结果的摘要或API的返回值。
智能体不断重复这个循环,将新的观察结果追加到历史记录中,现成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,并最后输出结果。
这种机制主要适用于以下场景:
需要外部知识的任务 :如查询实时信息(天气、新闻、股价)、搜索专业领域的知识等。需要精确计算的任务 :将数学问题交换辅助工具,避免LLM的计算错误。与API交互的任务 :如操作数据库、调用某个服务的API来完成特定的功能
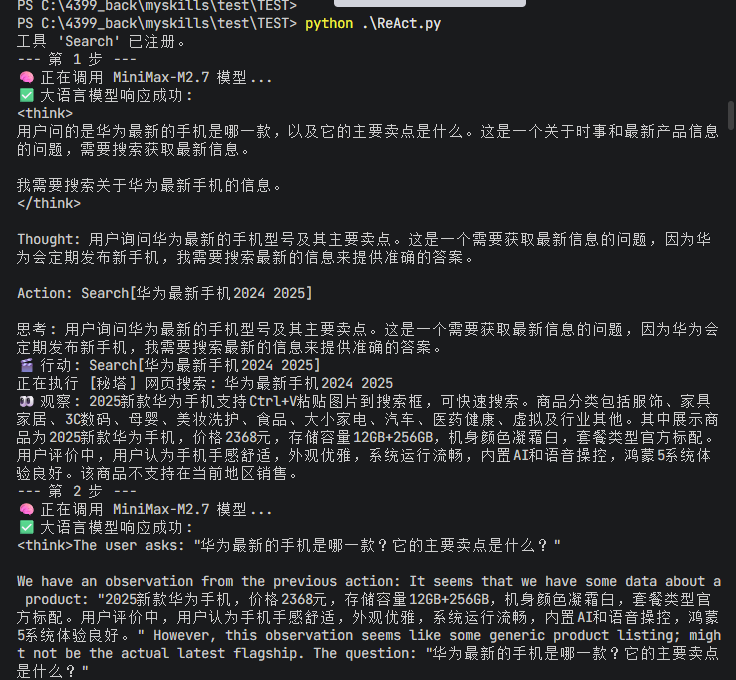
因此我们可以构建一个具备利用外部工具能力的智能体,来回答一个大语言模型仅凭自身知识库无法直接回答的问题,这里以问华为最新手机和买点为例,让智能体自己上网搜索,并调用工具。
2.工具的定义和实现 首先我们需要为智能体提供一个网页搜索工具,这里我们选择秘塔,之所以不用SerpApi是因为该内容是基于Google搜索的,考虑到国内使用还是用国内的较好,需要安装该库
同时前往官网注册免费账户,获取API密钥并添加到.env文件:
1 2 3 METASO_API_KEY ="YOUR_SERPAPI_API_KEY"
一个良好定义的工具应包含以下三个核心要素:
**名称 (Name)**: 一个简洁、唯一的标识符,供智能体在 Action 中调用,例如 Search。
描述 (Description): 一段清晰的自然语言描述,说明这个工具的用途。 这是整个机制中最关键的部分 ,因为大语言模型会依赖这段描述来判断何时使用哪个工具。**执行逻辑 (Execution Logic)**: 真正执行任务的函数或方法。
我们的第一个工具是 search 函数,它的作用是接收一个查询字符串,然后返回搜索结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 import osimport requestsfrom dotenv import load_dotenv"https://metaso.cn/api/v1" def _get_api_key () -> str :"METASO_API_KEY" )if not api_key:raise ValueError("METASO_API_KEY 未在 .env 文件中配置。" )return api_keydef _headers () -> dict :return {"Authorization" : f"Bearer {_get_api_key()} " ,"Content-Type" : "application/json" def search (query: str ) -> str :""" 一个基于秘塔(Metaso)的实战网页搜索引擎工具。 智能解析:优先返回 AI 直接答案,其次长摘要,最后是网页片段列表。 """ print (f"🔍 正在执行 [秘塔] 网页搜索: {query} " )try :try :f"{METASO_BASE} /qa" ,"q" : query, "model" : "r1" },60 "answer" , "" ).strip()if answer:return answer except Exception:pass f"{METASO_BASE} /search" ,"q" : query,"scope" : "webpage" ,"includeSummary" : True ,"includeRowContent" : False ,"size" : "10" 30 "webpages" , [])if not webpages:return f"对不起,没有找到关于 '{query} ' 的信息。" for page in webpages:"summary" , "" ).strip()if summary:return summaryf"[{i+1 } ] {page.get('title' , '' )} \n{page.get('snippet' , '' )} " for i, page in enumerate (webpages[:3 ])return "\n\n" .join(snippets)except requests.exceptions.Timeout:return "搜索时发生错误:请求超时" except requests.exceptions.RequestException as e:return f"搜索时发生错误:网络请求失败 - {e} " except Exception as e:return f"搜索时发生错误:{e} "
在上述代码中,首先会检查是否存在 answer_box或 knowledge_graph(知识图谱)等信息,如果存在,就直接返回这些最精确的答案。如果不存在,它才会退而求其次,返回前三个常规搜索结果的摘要。这种“智能解析”能为LLM提供质量更高的信息(网络实时)输入
接下来我们构造通用的工具执行器,当智能体需要使用到多种工具的时候,我们需要统一的管理器来注册和调度这些工具,微臣我们可以创建一个ToolExecutor类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from typing import Dict , Any , Callable , Optional class ToolExecutor :""" 一个工具执行器,负责管理和执行工具。 """ def __init__ (self ):Dict [str , Dict [str , Any ]] = {}def register_tool ( self, name: str , description: str , func: Callable [..., Any ], ) -> None :"""向工具箱中注册一个新工具。""" if not callable (func):raise TypeError(f"func 必须是可调用对象,收到: {type (func).__name__} " )if name in self.tools:print (f"警告:工具 '{name} ' 已存在,将被覆盖。" )"description" : description, "func" : func}print (f"工具 '{name} ' 已注册。" )def get_tool (self, name: str ) -> Optional [Callable [..., Any ]]:"""根据名称获取一个工具的执行函数,未找到返回 None。""" return self.tools.get(name, {}).get("func" )def execute (self, name: str , *args, **kwargs ) -> Any :"""执行指定名称的工具。""" if func is None :raise KeyError(f"工具 '{name} ' 未注册。" )return func(*args, **kwargs)def get_available_tools (self ) -> str :"""获取所有可用工具的格式化描述字符串。""" return "\n" .join([f"- {name} : {info['description' ]} " for name, info in self.tools.items()
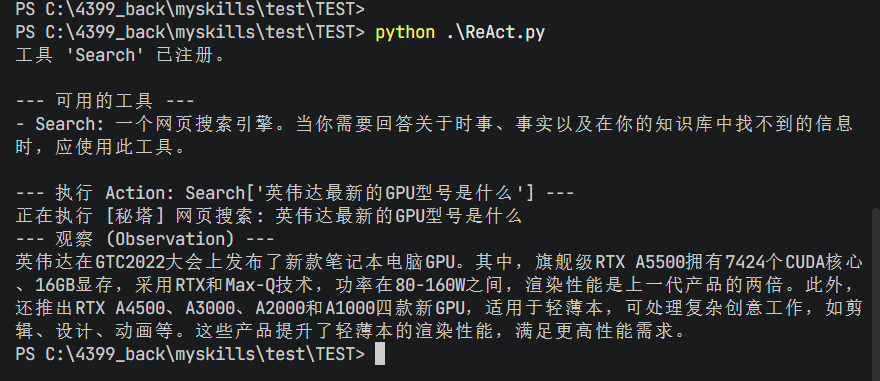
构造好类后,我们进行测试,将search注册到ToolExecutor中,并模拟测试一次调用,验证流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 if __name__ == '__main__' :"一个网页搜索引擎。当你需要回答关于时事、事实以及" "在你的知识库中找不到的信息时,应使用此工具。" "Search" , search_description, search)print ("\n--- 可用的工具 ---" )print (tool_executor.get_available_tools())print ("\n--- 执行 Action: Search['英伟达最新的GPU型号是什么'] ---" )"Search" "英伟达最新的GPU型号是什么" try :print ("--- 观察 (Observation) ---" )print (observation)except KeyError as e:print (f"错误:{e} " )
至此,我们已经为智能体配备了连接真实世界互联网的Search工具,为后续的ReAct循环提供了坚实的基础。
3.ReAct智能体的编码实现 有了前面独立的组件,LLM客户端和工具执行器组装起来,就可以开始构造一个完整的ReAct智能体,为了负变更理解,我们将类的实现拆分为了几个步骤
提示词是整个 ReAct 机制的基石,它为大语言模型提供了行动的操作指令。我们需要精心设计一个模板,它将动态地插入可用工具、用户问题以及中间步骤的交互历史。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 """ 请注意,你是一个有能力调用外部工具的智能助手。 可用工具如下: {tools} 请严格按照以下格式进行回应: Thought: 你的思考过程,用于分析问题、拆解任务和规划下一步行动。 Action: 你决定采取的行动,必须是以下格式之一: - `{{tool_name}}[{{tool_input}}]`:调用一个可用工具。 - `Finish[最终答案]`:当你认为已经获得最终答案时。 - 当你收集到足够的信息,能够回答用户的最终问题时,你必须在Action:字段后使用 Finish[最终答案] 来输出最终答案。 完整示例: Question: 法国的首都是哪? Thought: 这是一个常识问题。 Action: Finish[巴黎] 现在,请开始解决以下问题: Question: {question} History: {history} """
从代码中我们可以看到定义智能体育LLM大模型之间交互的规范,主要包括了四点:角色定义、工具清单、格式规定以及动态上下文
前面提到了,ReActAgent的核心是一个循环,通过不断的“格式化提示词->调用LLM->执行结果->整合结果”直到任务完成或者达到最大步数限制,这里我们需要先定义一个类别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class ReActAgent :def __init__ (self, llm_client: HelloAgentsLLM, tool_executor: ToolExecutor, max_steps: int = 5 ):def run (self, question: str ):""" 运行ReAct智能体来回答一个问题。 """ 0 while current_step < self.max_steps:1 print (f"--- 第 {current_step} 步 ---" )"\n" .join(self.history)format ("role" : "user" , "content" : prompt}]if not response_text:print ("错误:LLM未能返回有效响应。" )break
run是运行智能体的入口,通过while循环构成了ReAct范式的主题,max_steps参数则是一个重要的安全阀门,防止智能体陷入无限循环而耗尽资源
LLM返回的内容是纯文本,我们需要从中提取出Thought以及Action(因为前面在对LLM回答的规范中有设定要求)。这就需要我们通过几个辅助解析函数来进行操作,这些函数通常是使用正则表达式来实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def _parse_output (self, text: str ):"""解析LLM的输出,提取Thought和Action。 """ r"Thought:\s*(.*?)(?=\nAction:|$)" , text, re.DOTALL)r"Action:\s*(.*?)$" , text, re.DOTALL)1 ).strip() if thought_match else None 1 ).strip() if action_match else None return thought, actiondef _parse_action (self, action_text: str ):"""解析Action字符串,提取工具名称和输入。 """ r"(\w+)\[(.*)\]" , action_text, re.DOTALL)if match:return match.group(1 ), match.group(2 )return None , None
这里主要设计到两个辅助函数,第一个_parse_output是为了提取Thought以及Action,而_parse_action主要是为了获取action
通过辅助函数获取到内容后,接下来便是工具的调用与执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 if thought:print (f"思考: {thought} " )if not action:print ("警告:未能解析出有效的Action,流程终止。" )break if action.startswith("Finish" ):r"Finish\[(.*)\]" , action).group(1 )print (f"🎉 最终答案: {final_answer} " )return final_answerif not tool_name or not tool_input:continue print (f"🎬 行动: {tool_name} [{tool_input} ]" )if not tool_function:f"错误:未找到名为 '{tool_name} ' 的工具。" else :
这段代码是Action的执行中心。它首先检查是否为Finish指令,如果是,则流程结束。否则,它会通过tool_executor获取对应的工具函数并执行,得到observation
最后一步,也是形成闭环的关键,是将Action本身和工具执行后的Observation添加回历史记录中,为下一轮循环提供新的上下文。
1 2 3 4 5 6 7 8 9 10 print (f"👀 观察: {observation} " )f"Action: {action} " )f"Observation: {observation} " )print ("已达到最大步数,流程终止。" )return None
通过将Observation追加到self.history,智能体在下一轮生成提示词时,就能“看到”上一步行动的结果,并据此进行新一轮的思考和规划。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 import refrom LLM_Client import HelloAgentsLLMfrom tools import ToolExecutor, search""" 请注意,你是一个有能力调用外部工具的智能助手。 可用工具如下: {tools} 请严格按照以下格式进行回应: Thought: 你的思考过程,用于分析问题、拆解任务和规划下一步行动。 Action: 你决定采取的行动,必须是以下格式之一: - `{{tool_name}}[{{tool_input}}]`:调用一个可用工具。 - `Finish[最终答案]`:当你认为已经获得最终答案时。 - 当你收集到足够的信息,能够回答用户的最终问题时,你必须在Action:字段后使用 Finish[最终答案] 来输出最终答案。 完整示例: Question: 法国的首都是哪? Thought: 这是一个常识问题。 Action: Finish[巴黎] 现在,请开始解决以下问题: Question: {question} History: {history} """ class ReActAgent :def __init__ (self, llm_client: HelloAgentsLLM, tool_executor: ToolExecutor, max_steps: int = 5 ):def run (self, question: str ):""" 运行ReAct智能体来回答一个问题。 """ 0 while current_step < self.max_steps:1 print (f"--- 第 {current_step} 步 ---" )"\n" .join(self.history)format ("role" : "user" , "content" : prompt}]if not response_text:print ("错误:LLM未能返回有效响应。" )break if thought:print (f"思考: {thought} " )if not action:print ("警告:未能解析出有效的Action,流程终止。" )break if action.startswith("Finish" ):r"Finish\[(.*)\]" , action).group(1 )print (f"🎉 最终答案: {final_answer} " )return final_answerif not tool_name or not tool_input:continue print (f"🎬 行动: {tool_name} [{tool_input} ]" )if not tool_function:f"错误:未找到名为 '{tool_name} ' 的工具。" else :print (f"👀 观察: {observation} " )f"Action: {action} " )f"Observation: {observation} " )print ("已达到最大步数,流程终止。" )return None def _parse_output (self, text: str ):"""解析LLM的输出,提取Thought和Action。 """ r"Thought:\s*(.*?)(?=\nAction:|$)" , text, re.DOTALL)r"Action:\s*(.*?)$" , text, re.DOTALL)1 ).strip() if thought_match else None 1 ).strip() if action_match else None return thought, actiondef _parse_action (self, action_text: str ):"""解析Action字符串,提取工具名称和输入。 """ r"(\w+)\[(.*)\]" , action_text, re.DOTALL)if match:return match.group(1 ), match.group(2 )return None , None if __name__ == '__main__' :"一个网页搜索引擎。当你需要回答关于时事、事实以及在你的知识库中找不到的信息时,应使用此工具。" "Search" , search_desc, search)"华为最新的手机是哪一款?它的主要卖点是什么?"
4.ReAct 的特点
ReAct 最大的优点之一就是透明。通过 Thought 链,我们可以清晰地看到智能体每一步的“心路历程”——它为什么会选择这个工具,下一步又打算做什么。这对于理解、信任和调试智能体的行为至关重要。
与一次性生成完整计划的范式不同,ReAct 是“走一步,看一步”。它根据每一步从外部世界获得的 Observation 来动态调整后续的 Thought 和 Action。如果上一步的搜索结果不理想,它可以在下一步中修正搜索词,重新尝试。
ReAct 范式天然地将大语言模型的推理能力与外部工具的执行能力结合起来。LLM 负责运筹帷幄(规划和推理),工具负责解决具体问题(搜索、计算),二者协同工作,突破了单一 LLM 在知识时效性、计算准确性等方面的固有局限
5.ReAct 的局限性
ReAct 流程的成功与否,高度依赖于底层 LLM 的综合能力。如果 LLM 的逻辑推理能力、指令遵循能力或格式化输出能力不足,就很容易在 Thought 环节产生错误的规划,或者在 Action 环节生成不符合格式的指令,导致整个流程中断。
由于其循序渐进的特性,完成一个任务通常需要多次调用 LLM。每一次调用都伴随着网络延迟和计算成本。对于需要很多步骤的复杂任务,这种串行的“思考-行动”循环可能会导致较高的总耗时和费用。
整个机制的稳定运行建立在一个精心设计的提示词模板之上。模板中的任何微小变动,甚至是用词的差异,都可能影响 LLM 的行为。此外,并非所有模型都能持续稳定地遵循预设的格式,这增加了在实际应用中的不确定性。
步进式的决策模式意味着智能体缺乏一个全局的、长远的规划。它可能会因为眼前的 Observation 而选择一个看似正确但长远来看并非最优的路径,甚至在某些情况下陷入“原地打转”的循环中。
6.ReAct 的调试技巧
在每次调用 LLM 之前,将最终格式化好的、包含所有历史记录的完整提示词打印出来。这是追溯 LLM 决策源头的最直接方式。
当输出解析失败时(例如,正则表达式没有匹配到 Action),务必将 LLM 返回的原始、未经处理的文本打印出来。这能帮助你判断是 LLM 没有遵循格式,还是你的解析逻辑有误。
检查智能体生成的 tool_input 是否是工具函数所期望的格式,同时也要确保工具返回的 observation 格式是智能体可以理解和处理的。
调整提示词中的示例 (Few-shot Prompting):
如果模型频繁出错,可以在提示词中加入一两个完整的“Thought-Action-Observation”成功案例,通过示例来引导模型更好地遵循你的指令。
更换一个能力更强的模型,或者调整 temperature 参数(通常设为0以保证输出的确定性),有时能直接解决问题。