RAG--流程学习
RAG–流程学习
0.前言
前面我们提到了RAG的整体基本运行流程主要是分片、索引、召回、重排以及生成
1.分片
通用的基础大模型存在以下的一些问题:
- LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
- LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
- 幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息
- 数据安全性
因此RAG应运而生,也就是检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案,可以理解为 RAG = 检索技术 + LLM
2.RAG的双线架构
RAG的全称为Retrieval Augmented Generation,即检索、增强、生成。一般而言我们可以将RAG系统拆解成两条线来看待,也就是双线架构
- 数据装备阶段(业务线)
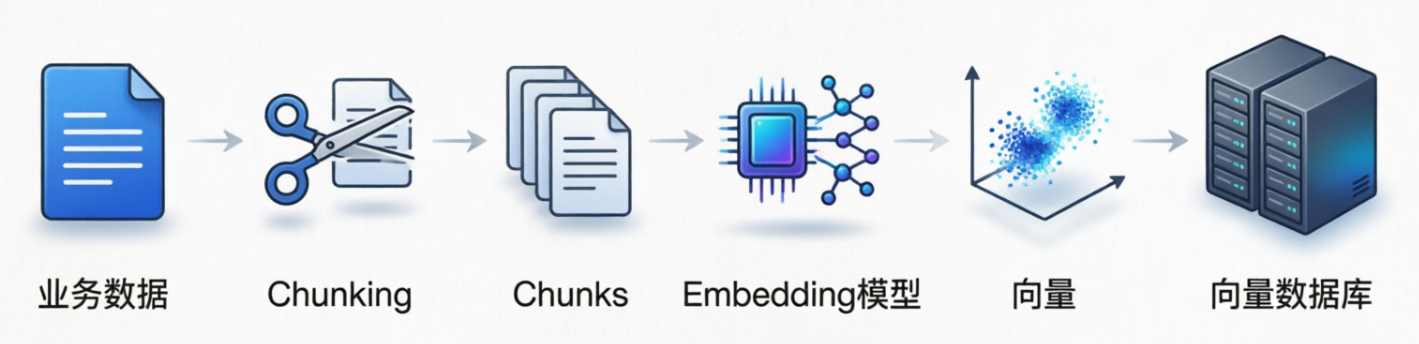
- 回答生成阶段(用户线)
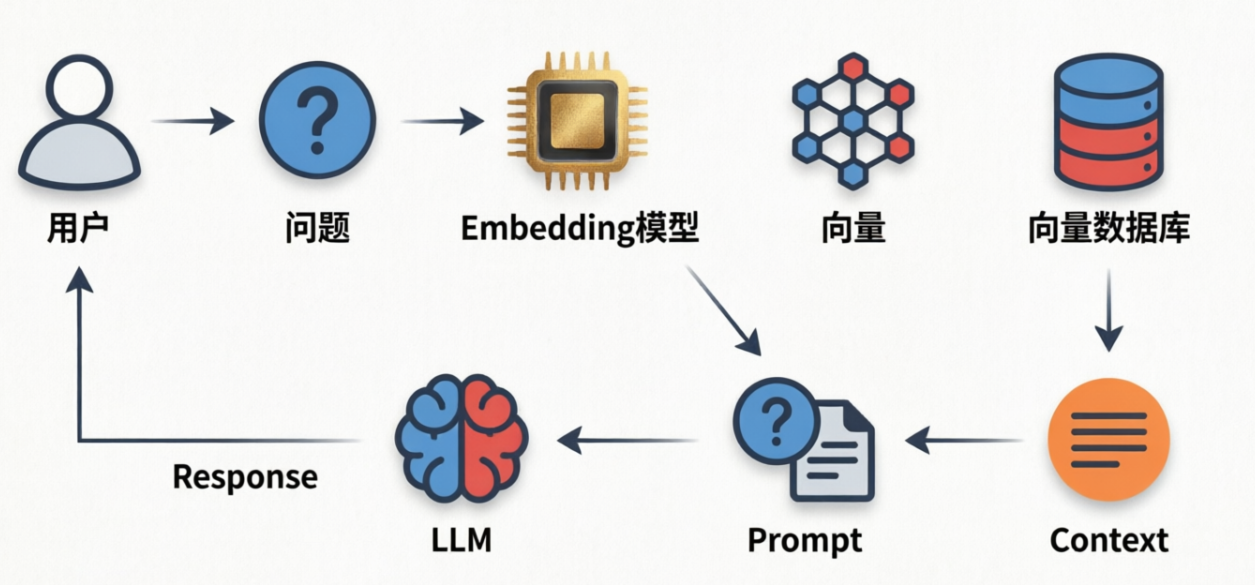
3.RAG商业落地的痛点
尽管从双线架构的层面理解,RAG系统是比较好实现的,但是如果要达到商业层面的交付还是需要注意很多痛点和问题的
- 痛点一:文档解析
在商业模式下,大部分的文件内容都是以PDF的形式存在,如果使用开源的PDF解析器进行拆解,可能会存在乱码和表格错位。针对问题的解决办法,我们需要使用专用版面分析模型 + OCR + 人工符合反馈(RLHF)的复合型方式进行文档解析,这是AI落地的第一道门槛
- 痛点二:颗粒度
当文档解析完毕后,对内容切片就成为了重要的问题,切片过大容易导致噪音多影响模型判断,切片过小又容易导致语义丢失,这里就需要根据业务场景大量测试分片的策略,一般在切片的同时会加入上下文重叠来使得损失最小化
- 痛点三:检索的准确率
检索的准确率不夸张的讲直接决定了RAG结果的生死,这里就涉及到混合检索(向量+关键词)和重排模型(Rerank)
- 痛点四:用户提问的模糊性
针对口语化、指代不明及语义模糊的提问,结合上下文进行信息不全与意图重构
4.RAG的大模型选项以及评估标准
目前市面上的大模型种类已经数不胜数,每隔个一段时间都会发布新的模型。但是并非所有的模型都能适合作为RAG系统的大模型基座。我们需要考虑的是模型的三个方面实力

5.RAG的进阶
除了常规的搭建,我们也会遇到很多不同的情况,例如实体关系错综复杂的需求,需要具备烧烤与拆解能力的智能体。GraphRAG(知识图谱)和Agentic RAG就此诞生,这只是两种比较典型的进阶版本,当基于后续的需求越来越复杂。更强大的构建方式也会随之产生